 Yesterday I demonstrated a bit of how I use Graphviz to visualize game information. I figured today I would describe a bit about how I get certain game data.
Yesterday I demonstrated a bit of how I use Graphviz to visualize game information. I figured today I would describe a bit about how I get certain game data.
Capture to MS Word
I have created a Word template containing many styles used primarily to mark the start of different game objects such as feats and spells. I copy and paste text from the source documents (web pages — Paizo PRD is surprisingly consistent when handled this way — and PDFs being the most common).
Preliminary Cleanup
If necessary I reflow the paragraphs where they are broken at line-ends.
The easiest way to do this is actually to put an additional paragraph break between them all paragraphs in the text I am working with, then use Search & Replace on special characters (quotes used below to delimit text being replaced, do not include in search or replace fields):
- ‘^s’ -> ‘ ‘
- ‘^p^p’ -> ‘^l’
- ‘^p’ -> ‘ ‘
- ‘^l’ -> ‘^p’
- ‘ ‘ -> ‘ ‘
- ‘ ^p’ -> ‘^p’
- ‘^p ‘ -> ‘^p’
In English: replace non-breaking spaces with regular spaces, double paragraph breaks with line breaks, paragraph breaks with spaces, line breaks with paragraph breaks, double spaces with single spaces, strip space at end of paragraph, strip space at start of paragraph.
The various paragraph and line break steps are important. The first replaces the now-doubled paragraph markers with a non-paragraph marker that I don’t use elsewhere, the next gathers the lines of the paragraph together into a single paragraph (more than that, really — all lines in the entire block being processed are grouped into a single paragraph!), and the step after that then separates the paragraphs where they should be separated. It’s a little hokey, but works quite well.
Edit 2015/07/17: I have since learned an even easier way to get most of the paragraph breaks. Do a global search and replace (with wildcards on) on:
- ‘^013[a-z\(]’ -> ‘ \1’
This replaces all end of paragraphs followed by a lower-case letter or left-parenthesis with a space followed by that lower-case letter or left-parenthesis. This joins up most of the incomplete sentences.
Apply Styles
This is usually pretty straightforward. Go through the document and apply styles where needed in order to section the document (usually two levels are sufficient, using Heading 1 and Heading 2) and mark the start of feats, spells, and other game objects. These primary styles are based on headings so they will show up in the Document Map. I also have some some general auxiliary styles for things like ‘Summary’ information (I mostly use this style with spell summary information).
Where needed I have some ‘subelement styles’. For example, ‘Class Feature’ is a style that identifies the start of a class feature such as Evasion or Rage Power, and ‘Class Subfeature’ identifies the start of a subfeature of the parent such as a specific rage power.
Additional Data Editing
I do some additional editing to help me with later processes. Some markup has evolved for certain things such as the level at which an ability can become available and ‘chain references’ (such as for spells that are defined in terms of each other). This doesn’t usually take very long.
Where I can I incorporate errata, and I make some other stylistic changes to make it easier to reuse the information later. This can be very time consuming and I do it only when it looks like I will soon be using the object in question.
Save and Export
Two distinct actions, because I keep the base source in Word format (DOCX) and export to ‘Filtered HTML’ because as far as I can tell it is the cleanest HTML Word produces. The ‘Filtered HTML’ files get copied up to my server (using a source control system — hosted on yet another server, so I always have at least three more or less complete versions extant in case I lose one or two) where I have the tools for the next step.
Transformations To Get Data
Okay, that’s got my first step done, raw text acquisition. Next comes a large number of transformations to extract data from this text.
- iconv to change the character encoding from WINDOWS-1252 codepage to UTF-8.
- htmltidy to convert the file from HTML to XHTML (XML-based HTML, so I can do further processing using XSLT).
- XSLT (via Saxon) to do basic semantic examination, stripping extraneous content such as the <head> element and to convert many of the XML elements from ‘generic Word element to more useful XML object’. Semantic only, no structure to speak of.
- XSLT to structure the document: nest <h1>, <h2>, <h3>, <h4>, <h5>, <h6> as needed. <xslt:for-each-group> is a game-changer in the evolution of XSLT from v1.0 to v2.0.
- XSLT to structure the game objects: group game object content: each game object starter (<feat>, <spell>, etc.) gets all following elements until the next such starter, so “<feat>name</feat><prerequisites>prereqs</prerequisites><benefit><p>benefit paragraph 1</p><p>benefit paragraph 2</p><feat>next feat</feat>” becomes “<feat name=’name’><prerequisites /><benefit /></feat><feat name=’next feat’ />” (some text elided to make structure more evident.
- XSLT to do element-specific parsing: break apart the prerequisites, including hierarchical components (‘or’ prerequisites: normally I can just have a <prerequisites> with multiple <prereq> children, but where there is a prerequisite satisfied by more than one option I need to nest them, one with a ‘type=”or”‘ and a child for each option); arrange other major fields such as ‘benefit’, ‘normal’, and ‘special’ (for feats), or parsing spell summary information, or pulling apart a class definition… classes are hard, by the way.
There are a few additional transformations to tidy up some things that would be troublesome to do in a single bigger step. In principle the entire suite of XSLT transformations could be done with a single XSLT file, but I believe it would be a prohibitively complex one. It’s much easier to segment the work into related work sets (preliminary cleaning and semantic, structure, game element parsing, etc.)
Transformations to Merge Data
That about covers the second step, which gets me most of my objects… for each file. I’m not done, though. Each of these output files gets imported into another master XML file and processing continues on the entire set.
- XSLT to merge all source files (as described immediately above).
- XSLT to order the objects by type.
- XSLT to group objects of like type into datasets (again, <xslt:for-each-group> is very useful)
- XSLT to join related content: ‘Rage Power’ is identified as a class feature in many data source files, and each contains definitions of the various rage powers. Combine all such class feature entries into a single one containing all the subfeatures. Similarly, spell lists are spread across many sources, merge them.
- XSLT to parse and if possible, precisely label prerequisites. For instance, a prerequisite of ‘rage class feature’ is parsed as a class feature, there is one called ‘rage’, so I create a <prereq> element that identifies that it requires a class feature called ‘rage’ and it is the <class-feature> with @id=”class-feature.rage”. If the type can be identified but no such object can be found (‘ragee class feature’ will not be found) it will still be identified as a ‘class feature prerequisite’ but will not have the specific reference ID and will be marked as ‘unknown’.
- XSLT to resolve data discontinuities, specifically including updating the ‘level’ field of spell summaries to include all spell lists and levels the spell is part of. I am probably going to add a ‘domain’ field to identify the domains and subdomains the spell is part of, and the level in each. I also use this step to apply archetypes to their base classes and create objects for the resulting variant classes.
That’s what, step three? I now have an XML file full of game objects. Now what?
Transformation To Apply Data
A lot of work has been done so far, now I get past the purely cerebral joy of extracting signal from noise (which, geek that I am, actually is pretty cool and exciting to see happen) and into creating something new from the data extracted.
PDF Files
The first goal I had was creating PDF files of related information: the Echelon Reference Series. This involves yet another series of transformations of an input XML file for each desired PDF.
- XSLT to import the data file produced as the last step of the previous stage.
- XSLT to copy objects of interest from imported data file; imported data file is now discarded.
- XSLT to transform XML to LaTeX source file
- xelatex to convert LaTeX source file to PDF (including ancillary programs such as makeindex).
This works pretty well, as far as my class and style definitions work. There is still some polish to be done.
Prerequisite Diagrams
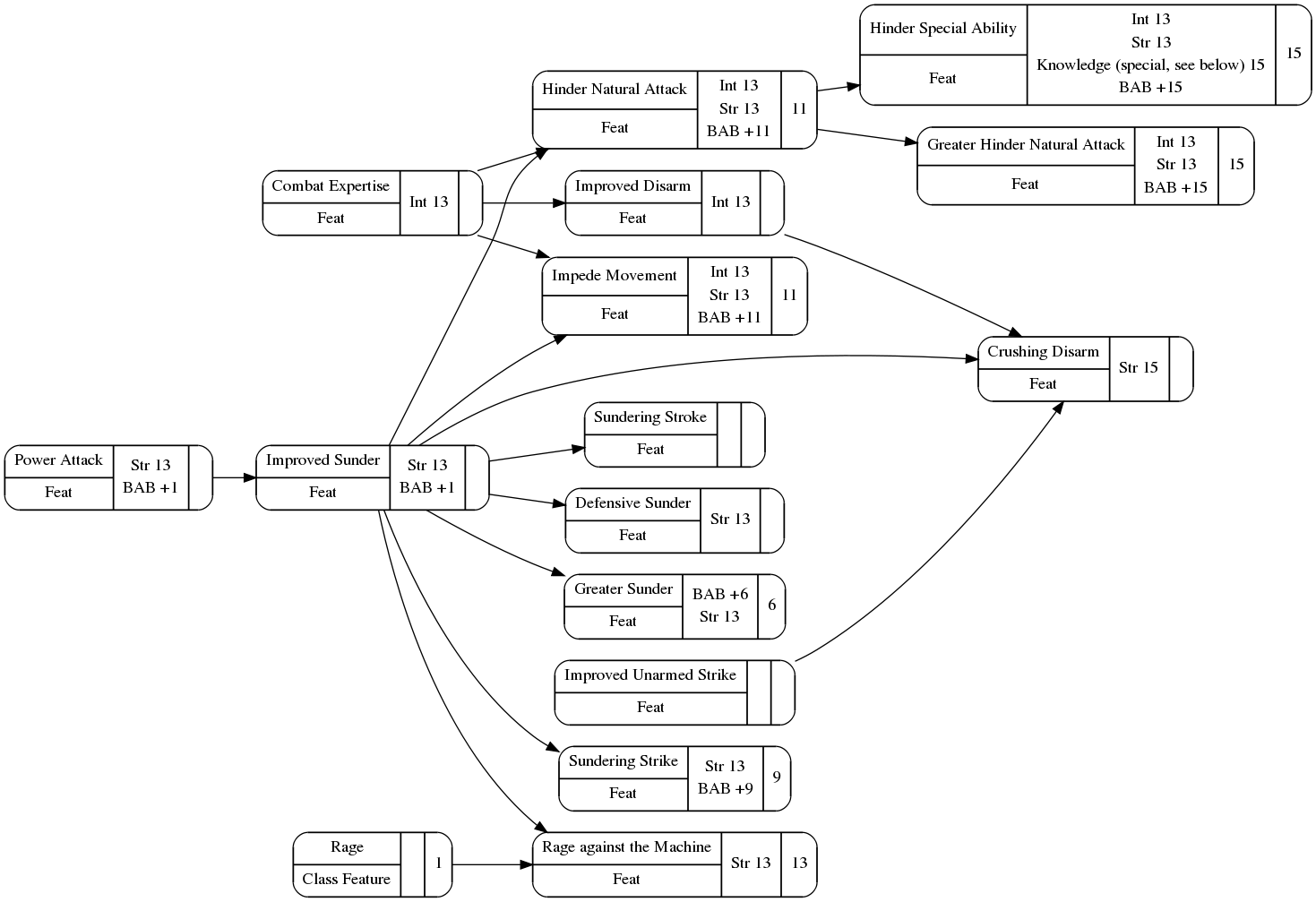
The prerequisite diagram I showed yesterday in Visualizing Game Information (and is included below) was machine-generated from the data file produced as the last step of the previous stage.
- XSLT to identify, for each game object of interest (meaning “has prerequisites or is a prerequisite of something else”) a minimal set of unique nodes to render and a minimal set of unique edges. Nodes may actually incorporate prerequisites (scores and skill rank prerequisites especially).
- XSLT to create a DOT file, for each game object identified in the previous step, containing all nodes and edges identified above, and all necessary attributes.
- Perl script to compile each DOT file into a PNG file.
At current count this produces 2,456 PNG files: 17 for classes, 167 for class features, 390 for specific class subfeatures (rage powers, bardic performances, etc.), 1,779 for feats, 36 for races, 25 for skills. 19 for spells, and 23 for other things.
PGF/TikZ Diagrams
Unfortunately, as useful as I find the machine-produced Prerequisite Diagrams, they… don’t work in my PDF workflow. I can import them, but frankly they tend to look pretty crappy by the time they’re scaled to fit the page. I found a LaTeX library that can be used to draw vector-based graphics — graphs such as the prerequisite diagrams produced by Graphviz. At this point I haven’t found a way to automate layout, but 2,456 is a lot of diagrams to do entirely by hand, even if many are quite simple. I’m replacing an earlier workflow component that took the DOT files produced above and parsed them to make a PGF source file (text file with LaTeX syntax, more or less, that defines the graph) with the nodes and edges, and needing only placement.
- XSLT to take the ‘pre-dot’ file produced by the first step of the Prerequisite Diagram process and for each game object of interest produce a PGF file containing definitions of all nodes and edges of interest, including level markers, and a comment indicating that the file was machine-produced.
- Perl script that examine each file produced above, compare it to the related file in the “include this in my LaTeX builds” directory, and replace the ‘build diagram’ with the new one if the build diagram has the ‘machine-produced’ comment. This allows me to create stub images for all diagrams and correct their layout as I go.
Many, and possibly most, diagrams may be a ‘single row’ of nodes. In these cases the stub image will require as many column inches as the final image, so they are useful to get a feel for page layout, even if they are simply a bunch of nodes on the same point.
Closing Comments
Yes, this is a lot of work. I am pleased with the results, though, even if I do periodically refactor pieces of the workflow as I realize easier ways or ways that produce better results.
Pingback: XML Workflow, A New Direction | In My Campaign - Thoughts on RPG design and play
Pingback: Evolution of the Echelon Reference Series | In My Campaign - Thoughts on RPG design and play
Pingback: Next Generation of the Echelon Reference Series | In My Campaign - Thoughts on RPG design and play