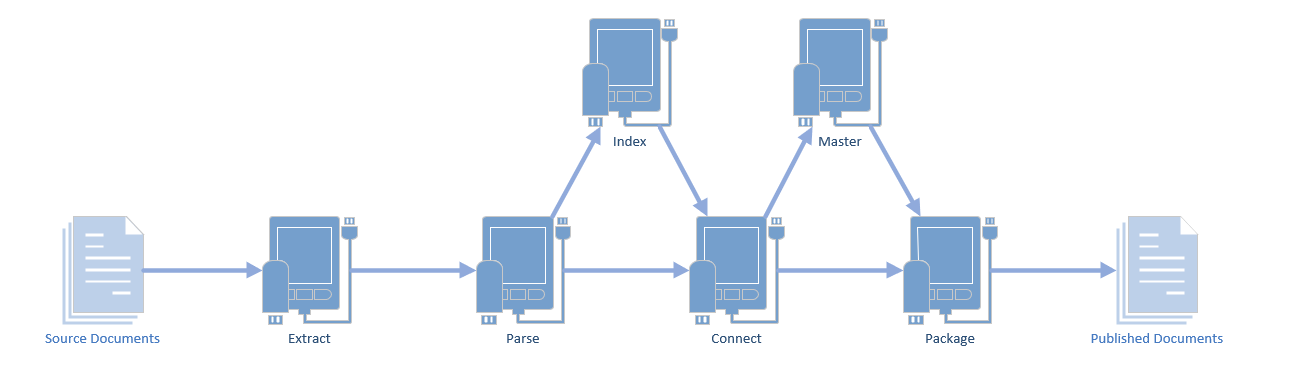
My publishing workflow covers many stages, which I’ll document here.
One of my quirks is that, as much as possible, I like transformations to be named in a monotonically-increasing manner. Once I get away from the source files (DocX and XlsX) and before I reach my output processing, I like the stages to be named in a way that sorting will tell me the processing order.
Weird quirk perhaps, but it does make my life easier.
Workflow Diagram
This diagram has seen many changes over the years, but should still be fairly recognizable.
This is the most recent version, from April 8, 2025. Previous versions, with varying amounts of supporting documentation, can be seen at
| Date | Link | Notes |
|---|---|---|
| 2025-04-07 | Flowing my Work | |
| 2024-10-04 | A Minor Refactoring, Redux | |
| 2024-10-02 | A Minor Refactoring | not actually the steps involved, but complete overhaul of how I manage the build process and Makefiles |
| 2024-09-26 | XML Workflow 2024-09-26 | |
| 2022-05-15 | XML Workflow, 2022-05-15 | |
| 2018-06-22 | Word -> PDF Workflow 2018-06-22 | |
| 2018-06-03 | Word -> PDF Workflow | |
| 2014-04-25 | Workflows for Extracting Data from Word Files | no diagram, but explains the process I used at the time… and have moved away from as I learned better |
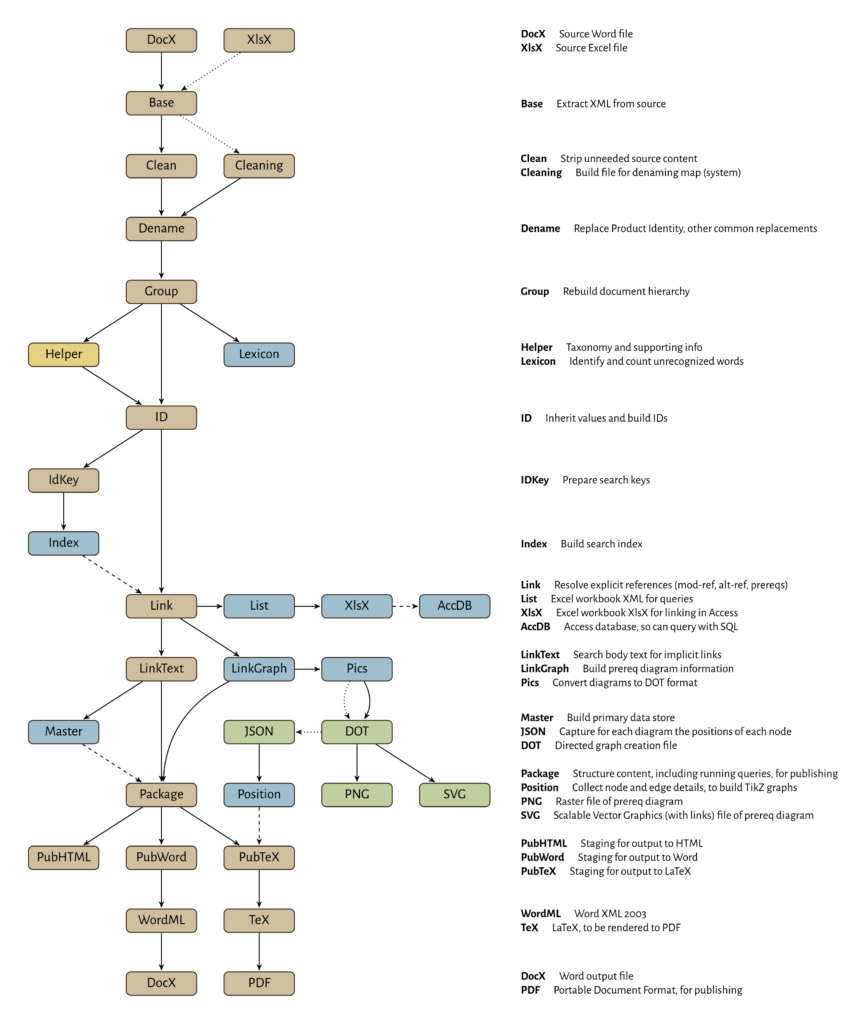
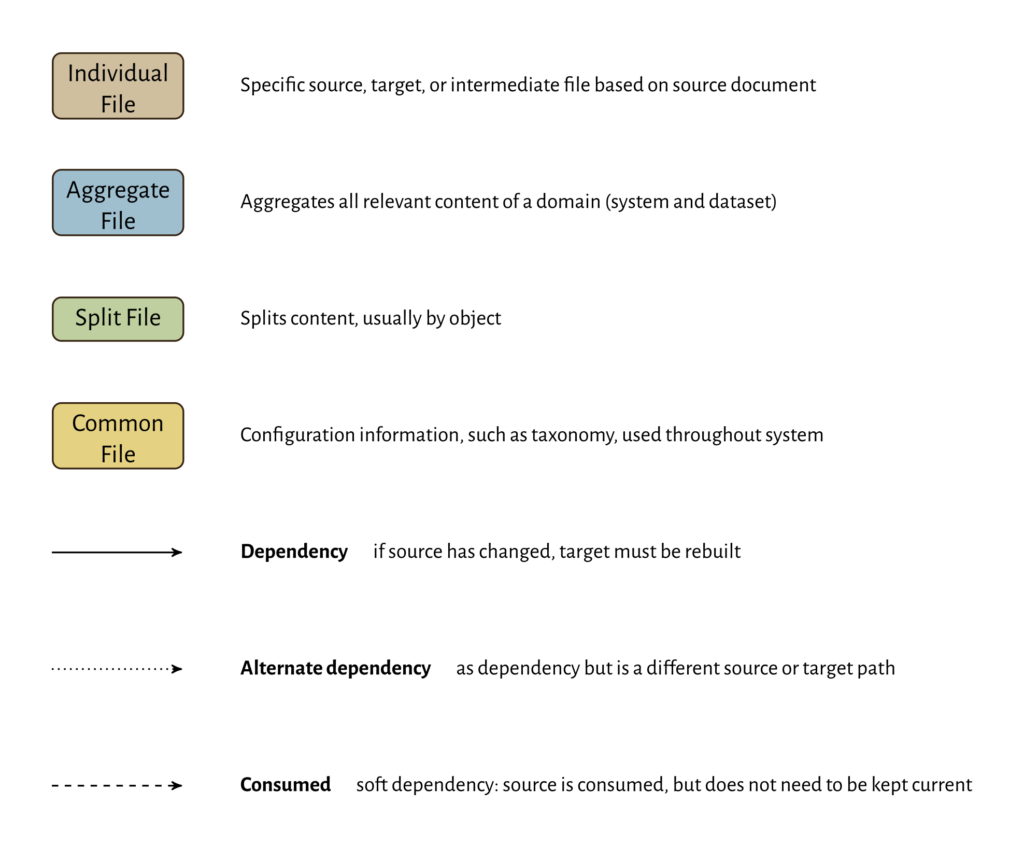
Transformation Stages
The data gets transformed in a series of stages, with some branches to create interim output (index files, link graph files to use in creating prerequisite diagrams, etc.).
| Stage | Type | Description/Notes |
|---|---|---|
| AccDB | Aggregate | Access database, links to XslX file to make tables I can query with SQL. |
| Base | Single | First stage of transformation, content is extracted from ZIP (DocX or XlsX) files, to be processed using XSLT. |
| Clean | Single | Word files contain many elements I don’t care about. This stage discards those elements. |
| Cleaning | Single | Process Excel workbook to create a file to be used in denaming — cleaning — Product Identity from my data set. |
| Dename | Single | Replace Product Identity (proper nouns, mostly) with different strings. Also correct common errors typically introduced as (de)hyphenation problems. For instance, if ‘full-round’ spans the end of a line, copying and pasting into Word often will strip the hyphen and leave me with ‘fullround’. I can fix those here also. System-specific rules, Product Identity is not shared between systems. |
| DocX | Input/Output | My documents start as Word files (DocX extension). These are ZIP files containing XML. DocX also is used as an output format later. |
| DOT | Output | Thousands of DOT files, to be processed by GraphViz to produce images and diagram placement details. |
| Group | Single | Rebuild the document hierarchy. Word stores blocks all at the same level: Heading 1 and Paragraph are shown hierarchically in the navigation pane in Word, but are stored as siblings in document.xml. Similarly, nested list elements all are stored as siblings (in the same level as Heading 1 and Paragraph). This stage rearranges those. Also, cracks document and object headings (see Markup) and starts building metadata. |
| Helper | Single | Taxonomy and Section 15 information files are created here and prepared for use in later stages. Section 15 is global (used by all systems), Taxonomy is system-specific. |
| ID | Single | Build object ID strings and copy information from taxonomy. Local metadata overrides inherited data. That is, if the taxonomy says to categorize an object one way, explicitly setting that field in the object will overrule the taxonomy. |
| IdKey | Single | Prepares content for integration into the Index file. This mostly means discarding all elements that are not game objects (or business domain objects) and building search keys for each object. |
| Index | Aggregate | Gather search information for all game objects and build an index to be used to resolve references. Domain-specific file (may have several per system). |
| JSON | Output | One file per diagram created, defining how the nodes and edges are arranged. To be consumed (Perl script?) to automatically generate files in other formats (PGF/TikZ in particular). |
| Lexicon | Aggregate | Counts all words by source, ignoring all words that appear in a dictionary. Outputs an Excel XML file I can turn into a Excel workbook for examination. Entries I find here will be copied to a file that will be used to build the Cleaning file above. System-specific file. |
| Link | Single | Resolve all implied links: mod-ref and alt-ref for things like subdomains and archetypes (mod-ref is the object being modified, alt-ref is a contextual aspect such as race for a racial class archetype) and prerequisites. Uses the Index file (master-sys-all.index.wml) but does not have a Make dependency. |
| LinkGraph | Aggregate | Identifies all potential nodes and edges based on object prerequisites, and bundles for processing into DOT (GraphViz) files and presentation as prerequisite diagrams. |
| LinkText | Single | Searches body text for implied links based on convention (feat names and skill names are capitalized, so seeing ‘Fly’ in the middle of a sentence likely means the Fly skill, while ‘fly’ might be a verb or refer to an insect; magic spells and magic items are typically italicized, and so on). Uses the Index file but does not have a Make dependency. |
| List | Aggregate | Creates an Excel XML file (to be converted to Excel workbook) identifying all the objects in the domain. Includes some other useful content such as all prerequisites, all mod- and alt- relationships, and so on. |
| Master | Aggregate | Gathers all objects that could be packaged for publication. This means all elements that have IDs (all game objects, supplementary objects that add to these, and all document objects with IDs) and their child elements. Domain-specific file. |
| Package | Single | Prepares the document for output: gathers information from the Master file for the domain being built, including supplementary information, and arranges for conversion to output formats. |
| Output | Final output file for documents, ready for print or reading. | |
| Pics | Aggregate | Processes diagrams defined in the LinkGraph file and outputs an XML manifest and a large number of DOT files. Classifying as ‘aggregate’ because it is built specifically from the LinkGraph aggregate file, but actually is a single-input transformation. |
| PNG | Output | Raster graphic file showing the prerequisite diagram for the game object. |
| Position | Aggregate | Collects position information from JSON files and automates TikZ translation, for inclusion in PubTeX files, and thus TeX and PDF. |
| PubHTML | Output | Preparing the Package file for transformation to HTML. Future work. Likely will consume Pics manifest file so either PNG or SVG can be used to display prerequisite diagrams. |
| PubTex | Output | Preparing the Package file for transformation to LaTeX. Includes things like reworking tables to align with LaTeX needs. Likely will consume Pics manifest file and automatically-generated PGF/TikZ diagrams. |
| PubWord | Output | Preparing the Package file for transformation to WordML. Future work. Haven’t decided if this should automatically include prerequisite diagrams, that could get immense. |
| SVG | Output | Scalable Vector Graphics file showing the prerequisite diagram for the game object. Nodes are hyperlinks to the matching object diagram. |
| TeX | Output | LaTeX file, to be compiled into PDF. |
| WordML | Output | Word XML file containing output document, to be converted to a DocX file for distribution. |
| XlsX | Input/Output | Some helper files are stored as Excel workbooks (XlsX extension). Also are ZIP files containing XML. XlsX also is used as an output format later, listing objects and provenance. |
File Naming Conventions
With the exception of the Input and Output files, all processing above is done using XML. By convention, files are named by ‘stage.wml’ (compact XML — no extraneous spaces or line breaks), and can be converted to ‘stage.xml’ (‘pretty printed’, with white space and line breaks) to make it readable. All processing is done using the WML files, the XML files are a courtesy to the developers when troubleshooting code.
For example, when processing egd-draconic-bloodlines.docx, after the document hierarchy is built I have a file called ‘egd-draconic-bloodlines.group.wml’. This file is hard for a human to read, so I run it through xmllint to get ‘egd-draconic-bloodlines.group.xml’.
Aggregation files are named either by data set or by domain. Each aggregate stage has ‘files-sys–set‘ and ‘master-sys–domain‘ files. The first aggregates data for the system data set, the latter aggregates data for the system domain. That is, ‘files-pf1-prd.index.wml’ contains the aggregate data for the PRD set, and ‘master-pf1-all.index.wml’ contains the index for the entire Pathfinder 1e data domain (‘master-pf1-pzo.index.wml’ excludes third-party content, but does include the PRD, PZO, and supporting content).
Other file types (XSLT, Word, Excel, etc.) use file extensions consistent with their standards.
Revision History
| Date | Revision |
|---|---|
| 2025-04-15 | Updated workflow diagram and moved to top. Transformation Stages is now long enough it makes more sense as an appendix to the diagram. Also, reordered stages by name rather than transformation order. With the number of transformations and the branches, easier to find things by name. |