Sometimes, “what it is” can be much more complicated that “how to work with it”.
My publishing workflow has seven different systems (including a ‘nosys’) with thirteen different domains (collections of content with that system).
- age — AGE System
- all (3pp, grr)
- grr (grr)
- d20 — d20 (D&D 3e, 3.5)
- all (3pp, srd)
- srd (srd)
- jtr — Just The Rules
- all (egd)
- lfg — Low Fantasy Gaming
- all (3pp, lfg)
- lfg (lfg)
- nosys — Non-system (not gaming related)
- all (egd)
- pf1 Pathfinder Roleplaying Game 1e
- all (3pp, ers_common, ers_data, prd, pzo)
- prd (ers_common, ers_data, prd)
- pzo (ers_common, ers_data, prd, pzo)
- true20 — True20
- all (3pp, grr)
- grr (grr)
The pf1 set is the only one I’ve published, the rest have been captured for my use.
My workflow has many steps, each of which needs me to define make rules. This gets tedious to maintain by hand, especially when I change how something works, so I’ve scripted aspects of the Makefile management.
The original script was built on an ad hoc basis, within new pieces being added as my workflow developed… and it wasn’t very well documented. There were three distinct build modes (single file, aggregation, simple), so when I wanted to add a new build stage it really wasn’t clear how to do so.
Time to rewrite. I started by defining a data structure (of course) that described each stage, along with the needed information. Then I needed to write code to transform this content into the actual make rules… and it was convoluted enough to get painful.
Okay. Time to take a step back. A make rule (in a simple sense) has only three pieces:
- target (what the rules lets you build)
- dependencies (what is needed, to build that target)
- build instructions (how to actually build the target)
The transformation of a DOT file to a PNG looks like (well, quite close to — the second line is supposed to have a tab rather than two spaces)
%.png: %.dot
@$(DOT) -Tpng $< -o $@The target patterns were basically fixed, the dependencies all take the form of (source file pattern, transformation script (where applicable), other dependencies). Some build instructions call a command line program instead of applying an XSLT script, so I made allowance for that.
At this point I realized I didn’t need to accurately represent the structural relationships between all the pieces. All I need is the content for each section. Each rule can be a single row in a spreadsheet.
Which is what I did.
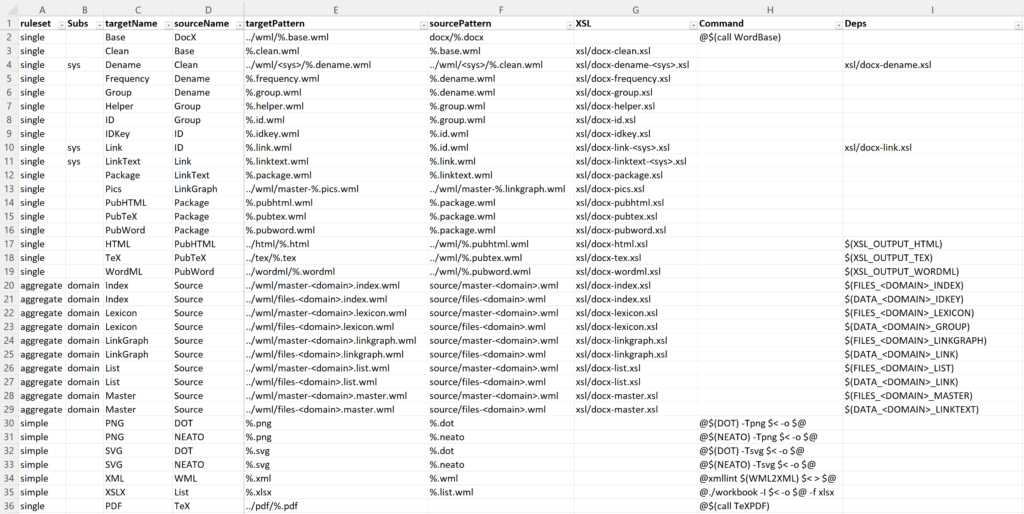
The first column can be ignored, the second indicates any substitutions that need to be made (system, or system and domain), then there are two templates for the make rules.
targetPattern: sourcePattern XSL Deps
@$(call transform,sourceName,targetName,XSL)
targetPattern: sourcePattern Deps
@$(call echo,sourceName,targetName)
CommandThis still means a lot of rules in the Makefile. Three of the base rules need to be broken out by system (seven output rules each)
- dename, different games have different Product Identity, so they different string substitutions.
- Really this should be a data file, and the script will be the same. I’ll still need different rules to manage the dependency on this data file.
- Right now the denaming files are XML files, I’ll be moving these to Excel workbooks as my source — another build rule to be added!
- link and linktext, different games have different rules based on formatting conventions and game objects.
The aggregation targets differ not in the build rules, but in the dependencies. Ten of the base rules need to be broken out by domain (thirteen output rules each).
- files-<domain> targets aggregate information for the individual data sets, the list of files by input stage for each is stored in a variable.
- master-<domain> targets aggregate information via the files-<domain>, the list of files-<domain> files for each is stored in a variable.
All in all, this means I have
- 35 input rules
- 3 of which get broken out into 7 output rules.
- 10 of which get broken out into 13 output rules.
- 35 – 3 – 10 + 3*7 + 10*13 = 163 rules altogether
Moving ahead though, this should all be easier to maintain.
- A new system, I add to my system list along with its domains and data sets.
- if I wanted to add Pathfinder 2e, I’d add ‘pf2’ system, ‘all’ and ‘pzo’ domains, and probably ‘3pp’, ‘ers_common’, ‘ers_data’, ‘prd’, ‘pzo’ data sets.
- A new domain, I just add as above but to an existing system.
- If I want a ‘non-PRD’ domain for the pf1 system, I’d just add ‘nonprd’ domain with ‘3pp’, ‘ers_common’, ‘ers_data’, ‘pzo’ data sets.
- A new data set, I just add to the appropriate domains.
- Pathfinder has a couple of specially-licensed supplements I have not included to date: ‘Vampire Hunters’ (based on Vampire Hunter D) and ‘Sword Devil’ (based on Red Sonja). They are not included in the ‘pzo’ data set, but I might capture that content and keep it in a ‘pzo-licensed’ data set, and add it to a new ‘private’ domain.
- A new transformation stage, I add to the rules workbook shown above. For instance, to make the change to the Dename rule described above, I would
- Add a new rule [single, Base, XlsX, ../wml/%.base.wml, docx/%.xlsx, , @(call ExcelBase)]
- Add a new rule [single, Cleaning, Base, %.cleaning.wml, %.base.wml, xsl/docx-cleaning.xsl]
- Modify Dename to change XSL to ‘xsl/docx-dename.xsl’, and add ‘../wml/<sys>/<sys>-dename.cleaning.wml’ to Deps.
- Add xsl/docx-cleansing xsl file to reformat Workbook XML to the XML I need.
- Modify xsl/docx-dename.xsl to use the cleaning file.
Then rebuild the Makefile and I’m set. That last example has several steps, but they’re each pretty simple to set up.