ANYWAY, over time my document workflow has changed a few times. Here’s the latest iteration, for those who wish a look into the mind of someone not quite right (and so I have a copy to remind myself how I’m doing this).
Not three weeks after I wrote that, I have an update to it.
Deep geekery ahead. The first big chunk is unchanged, but the last bit has wobbled some.
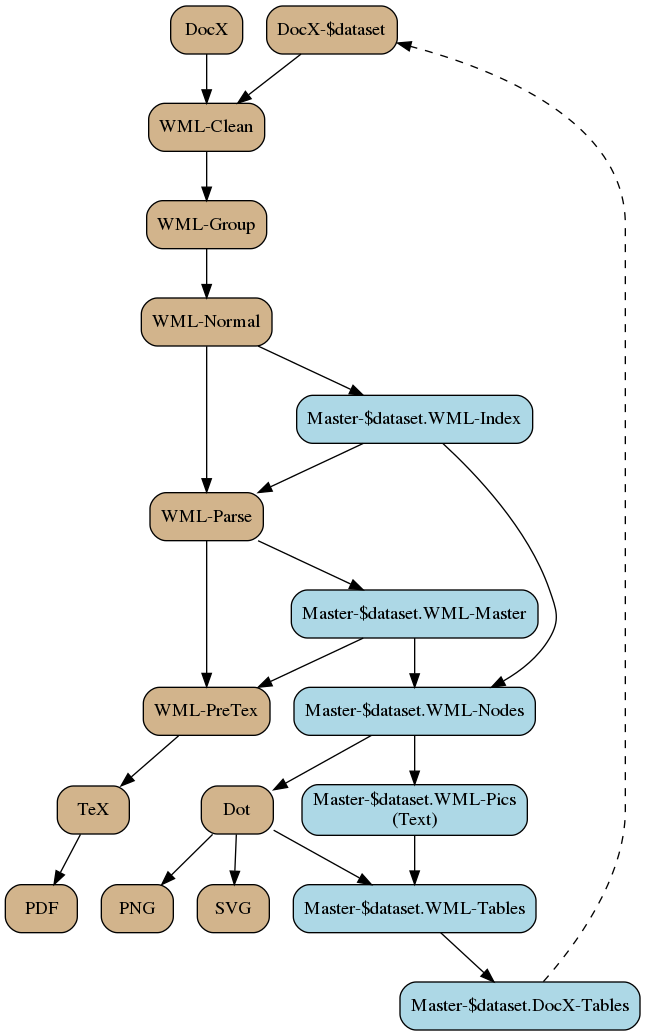
Document Transformations
The first step is reasonably straightforward. I have a Word file (specially formatted using styles) that I transform to XML, then run several transformations until I get to an XML data file that is a mix of document and game object information. Under the covers a Word ‘DocX’ file is a ZIP file containing XML files, so this is not as horrible as it sounds.
Bold, italic text indicates something new or changed.
| File Extension | Content |
|---|---|
| DocX | ZIP file containing document information in XML format. Ignore most of the files, but pull out document.xml, styles.xml, and numbering.xml. The first contains the actual document content, the second contains details of the styles used in the document (which I use later to identify object types and data structures), the last contains details of list types (so I can tell the difference between bullet lists and numbered lists, where I haven’t applied specific styles to the paragraphs).
I now have support for ‘diagram tables’. A diagram table is a table with the ‘Table Egd Diagram’ style, and has three nested tables. One subtable contains a matrix showing the relative location of the diagram nodes, by object ID (or synthesized ID if no such object exists — ad hoc prerequisites or andnodes/ornodes). Another subtable identifies the edges between the nodes (src, dest) and their attributes (alternate out and in ports, color, etc.), plus any node that gets placed on the edge (such as number of ranks in a skill). The third subtable has details about the nodes themselves (label to put in the node, node style, attributes expanding on or overriding those from the style). I have considered another option, for basically freeform TikZ encoded layout, but I’m hoping to not need that. |
| WML-Clean | XML file containing the document after applying details from the style and numbering definitions, and stripping all the extra stuff Word includes that I don’t care about (such as table column widths, spelling- and grammar-check markup, and so on). |
| WML-Group | XML file containing now-hierarchical document. Word treats a document as a series of blocks, with no document hierarchy inherent in the file. That is, it is much like HTML: a Heading 1 paragraph and Heading 2 paragraph look in Word as if one is nested inside the other, but they’re actually siblings (same parent object). This transformation builds the document hierarchy up I have a document section ‘level 1’ with a document section ‘level 2’ inside it. It also builds list hierarchies (so I can have nested lists) and nested hierarchies for game elements (such as class features inside a class). |
| WML-Normal | XML file with the same document structure, but now with game objects correctly identifying the game object type. As part of the grouping, I have ‘declarations’ (d20-#-Decl style) with objects nested within them. As part of normalizing, each object is assigned a type (and sometimes a few other things) from the nearest parent declaration. There is no inherent link between depth (declarations and objects run from levels 1..4) and the content: most often I use ‘d20-3’ for game objects such as spells. If I had a monster with a unique spell, though, the monster might be defined as a ‘d20-3-Object’ containing a ‘d20-4-Object’ for the spell.
In any case, this step removes the intermediate elements used for classifying the information: I can now know enough to explicitly identify the objects, without necessarily knowing anything more about them. (That’s the next step.) At this point I have also converted the ‘diagram tables’ from tables to actual diagram-specific elements. |
| Master-<dataset>.WML-Index | These files aggregate game data by dataset (PRD-Only, 3pp+PRD, etc.). All source WML-Normal files that land in this data set are included in the WML-Index file
Because I now know all the objects present, I can build an index I can use to search for things. For instance, if I find text in italics, I can search the lists of spells and magic items to see if there is a match. If I get a unique match (‘fireball’, say, matches just the spell) I can consider this a link. The ‘master’ files are built from the WML-Normal files. All files for a particular data set are loaded, extraneous information discarded so I have only the game objects (with ‘group IDs’ based on object-type.object-name, and full IDs that include parent objects if any). Evasion is a class feature of the monk, ranger, and rogue classes (among others, but we’ll start with this). I have a <d20:object> with ID and group ID ‘class-feature.evasion’, containing child <d20:object> elements with IDs ‘class-feature.evasion!class.monk’, ‘class-feature.evasion!class.ranger’, and ‘class-feature.evasion!class.rogue’. I also have ‘universal-rule.evasion’, ‘ninja-trick.evasion’, and so on, but they are at the same level as ‘class-feature.evasion’. This seeming redundancy is important in the next step. I also copy presentation information from the taxonomy into each index entry. This is redundant and I mostly don’t use it for text processing, but in the parsing stage I pull content from the index entries into the diagram tables, so it’s convenient. |
| WML-Parse | At this point I have structured the document and the game data pretty well, but I don’t know anything about it. This stage examines the document and object text to learn more about it. Links (explicitly identified by ‘ref styles’ such as ‘ref Feat’) or implicitly by formatting (italics are often an indicator of spell names or magic item names) can be identified and established. The italicized fireball actually looks something like <doc:text format=”italics” refid=”spell.fireball” reftype=”spell”>fireball</doc:text> in XML.
Similarly, prerequisites (previously extracted but not examined) can be resolved. A prerequisite of “Critical Focus” matches only one top-level indexed object (feat.critical-focus), and is easily resolved. Precise Shot, however, cannot (I expect somewhere a class has a ‘precise shot’ feature that… grants the Precise Shot feat). If the prerequisite were ‘Precise Shot feat’ (which resolves to only one object) or was ‘Precise Shot’ with the ‘ref Feat’ style (and I have other means of resolving conflicts) it would work. When I start this step, I have parsed the ‘diagram tables’ into diagram-specific elements. The diagram tables are driven by object IDs, and I have an index full of object IDs, with the object names, types, and presentation information from the taxonomy. For each node that matches an index entry (by ID) I copy the object name as the node label (if I don’t have that in the diagram table) and the presentation information (if I don’t already have that in the diagram table) into the diagram nodes. |
| Master-<dataset>.WML-Master | As Master-*.WML-Index, these files (one per dataset) have all the game objects from the source documents (each aggregates all relevant WML-Parse files). Later process will draw from these files to produce the actual documents. |
| WML-PreTex | These documents contain all content to go into the PDF. The WML-Parse file is loaded and the relevant master dataset file, and all ‘refcopy’ elements pull the associated game objects. A ‘refcopy’ element can be a specific ID (“feat.alertness”) or can be wildcarded (“rogue-talent\..*” pulls all rogue talents). This actually splits on dataset, depending on the WML-Master dataset used. |
| TeX | After the WML-PreTex file is created, it gets transformed to a LaTeX file, which will in turn be transformed to PDF. This is not an XML file. |
| Finally! The TeX file is converted to PDF. Indexes are constructed, references within the document are hyperlinked, and so on. | |
| Master-<dataset>.WML-Nodes | For every object in the dataset’s index file, trace through the related dataset-and-PRD master file (so for the 3pp dataset, trace through the 3pp+prd master file) and identify the prerequisite relationships between the indexed object and the other objects in the dataset and the PRD. I want to get the diagram information for every item in the dataset, and only for those items, but that examination requires information from the PRD as well. This file contains the information needed to prepare diagrams showing the relationships between game objects. |
| Master-<dataset>.WML-Pics | This actually is not an XML file, but I kept the naming convention so the files will group and sort in processing order. This is actually a catalogue file identifying the diagram (DOT) files produced from the nodes file. Each line is a tuple containing (object ID, object name, DOT file name, simple DOT file name). The ‘DOT file name’ is the name of the DOT file containing all the nodes, the ‘simple DOT file name’ is the name of the DOT file containing a simplified diagram with the ‘measurables’ embedded in the nodes (such as class levels, score values, and so on. Keeping the measurables in the diagram as standalone nodes tends to make very cluttered diagrams. The WML-Pics file gets read by a Perl script and the content processed to make the WML-Tables file. |
| Master-<dataset>.WML-Tables | A Perl script reads the WML-Pics file and processes each DOT file into a ‘plain’ file (captured as input; no file is created). The plain file contains simple descriptions of the nodes and edges, and their placement. The script uses the positioning of the nodes as identified in the ‘plain’ file to arrange them in a diagram table as described above (hence the file name), and includes the node and edge information. This is all WordprocessingML, as is used by Word DocX files. |
| Master-<dataset>.DocX-Tables | These files actually have a DocX extension and are created in the diagrams/$dataset directory. I take the document.xml file from a template DocX file and replace its <w:body> element with the one from the WML-Tables file. This gets zipped back into a copy of the template DocX file in the diagram/$dataset directory. |
I had originally planned to create HTML files that I could copy diagram tables from, but realized that it was actually easier to generate the tables in WordML instead and just go straight to Word. This removes a slew of manual steps in converting the machine-generated diagrams to diagram tables in Word.