I’ve been on something of a hiatus for the last little while. I work in the social sector — the part of the provincial government that provides more or less direct support to vulnerable citizens — and the last couple years put unprecedented demand on us.
It’s been tiring.
In any case, I’m getting back to publishing, including the Echelon Reference Series. While on vacation last October I started refactoring my workflow to better accommodate some weird edge cases in the source data, and to make parsing more contextually aware.
This is a long and bumpy post, more for the benefit of the writer (to help order my thoughts) than for the reader (to understand what I’m doing).
Data Modeling Challenges
There are two primary drivers behind the current refactoring. Both are to make my engine more capable and sophisticated, hopefully without invalidating the data encoding I’ve done already.
Objects with Multiple References
The biggest challenge has to do with referencing objects. For instance, an archetype modifies a class and may be associated with a race. I had that well in hand, and could easily indicate the modified object and the associated object. There were a few exceptions (subdomains that could be applied to two domains, mostly) but I had a kludge to work around that.
Then I started seeing archetypes that apply to more than one class (monk and unchained monk, or barbarian and unchained barbarian, mostly). I could apply the same kludge as subdomains (duplicate the archetype) or come up with something else. Eh…
And then I started seeing associated references that were to modified objects. For example, there could be an archetype that modified a class and was associated with a ‘subrace’ (what we used to call a variant of the base race — drow and duergar were in several editions ‘subraces’ of elf and dwarf respectively).
This became a problem, because I had no good way to encode an association to a modified object. The way I was doing it, the references themselves became part of the object ID string, and while I’m sure I could come up with a kludge to get around it (special-case construction of IDs) I realized that it was only a matter of time before something would invalidate that as well.
Also, I hate special-case coding.
History of Object ID Construction
In my day job, we often use surrogate keys in our databases. These are numeric values that are created within the database to identify records and managed by the database. Lovely, works great, not really practical here because it’s either really hard to maintain or really time-consuming to rebuild as needed.
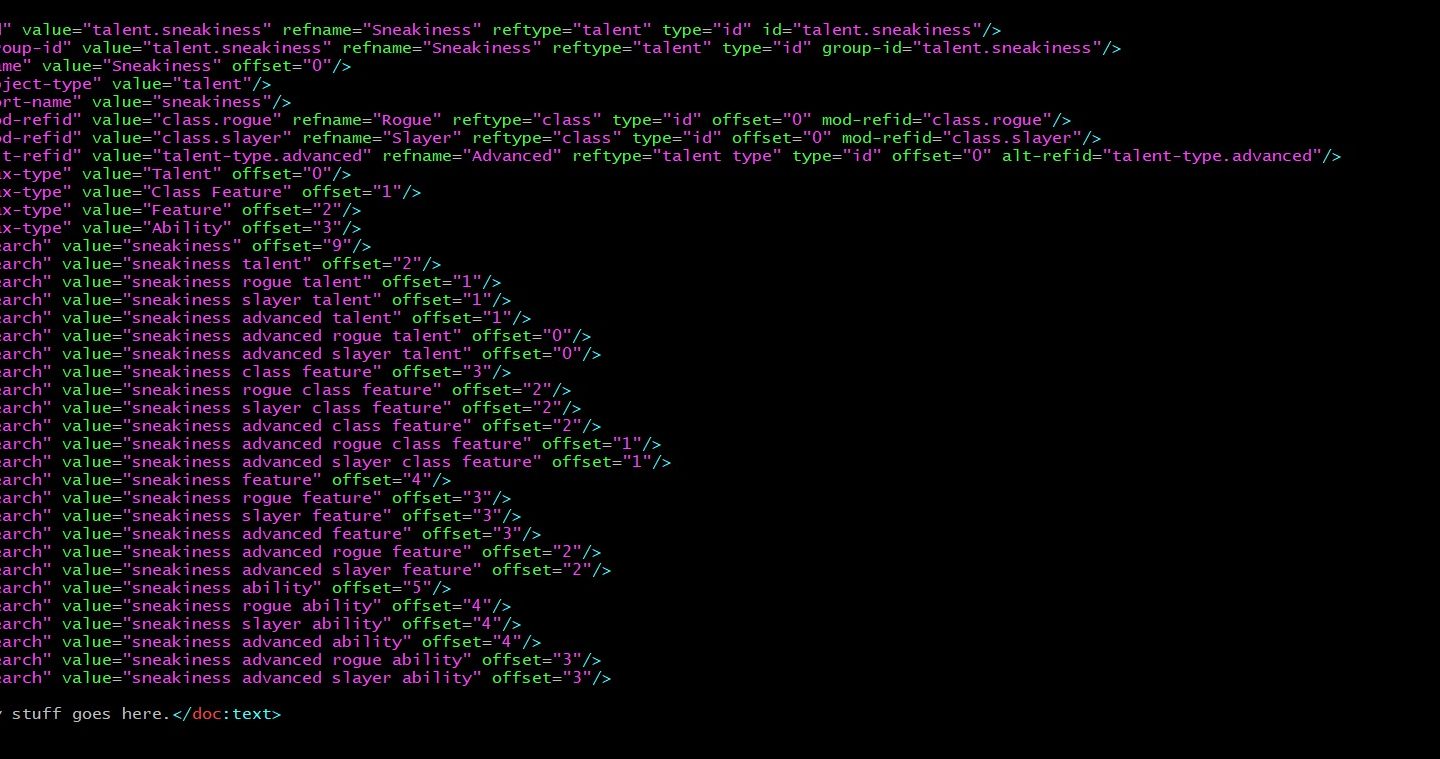
Basic IDs: I use ID strings made by concatenating key data. At its base, an ID is ‘type.name’: the sneak attack class feature has the ID ‘class-feature.sneak-attack’. This falls down in a few ways, most notably here because many classes have this feature.
IDs of Child Objects: One of the most common ID collisions is because multiple ‘parent objects’ have ‘child objects’ with the name name. Class features are a major example of this, with many classes having features such as ‘sneak attack’, ‘bonus feat’, ‘spells’, and so on. I started to append the ID of the parent object, if any. The rogue sneak attack class feature ID is now ‘class-feature.sneak-attack/class.rogue’.
IDs of Same-Named Objects: Sometimes, two objects are defined of the same name and type, but otherwise with no relationship. Feats and spells are the most common cases here. I took to adding a suffix to the name of the objects, which got incorporated into the object ID. For instance, if two source documents have a feat, ‘Sneaky Bugger’, each might get an abbreviation of the source title or publisher name appended. Typically if both were third-party content they both get a suffix, if only one is and the other is Paizo, only the third-party object would get a suffix. In some cases Paizo had duplicates, in which case PRD would remain unchanged and the non-PRD version would get a suffix (if the definitions were consistent enough I would simply keep one and make the other a refcopy in source). In a small number of cases there were objects with the same name and type within the same source document (favored class options… they aren’t even named in the original source, I added names so I could differentiate them in text; oh how I dislike favored class options, the whole mechanic).
IDs of Same-Named Modified Objects: It became valuable to me to be able to identify objects that modified other objects, and the objects they modified. That is, for an archetype it would be good to know what class it modified, and if relevant, the associated race. So many things are defined as “like that, but different in these ways”, and my object selection mechanisms were based on object IDs. I found it useful to append the modified object ID and associated object IDs to the object. If there are two sniper archetypes (for fighter and rogue), they could end up with object IDs of ‘archetype.sniper=class.fighter’ and ‘archetype.sniper=class.rogue’. For the sake of the example, let’s say there’s also a sniper ranger archetype is associated with the elf race; it gets the object ID ‘archetype.sniper=class.ranger!race.elf’. Yes, this is getting awkward… and then when we find out the sniper ranger archetype is associated with wood elves specifically, it might become… ‘archetype.sniper=class.ranger!subrace.wood-elf=race.elf’. I don’t really care about the length of the string, and it’s machine-generated anyway, but I didn’t have a way to encode that in my data files. (I probably could have done it by assigning orders of precedence to the IDs, but that makes them a little more brittle, and I still didn’t have a way to encode them in my input data, without setting them explicitly by hand. Not doing it.
IDs of Objects Modifying Multiple Base Objects: Demon subdomain modifies the Chaos and Evil domains. I kludged around this for a while by just defining it twice (once for Chaos, once for Evil) because there weren’t that many examples. And then I started seeing more and more, with more complex objects doing the modifications. It was getting to be too much trouble to define this way. I could have tried allowing multiple reference IDs in the object ID (subdomain.demon=domain.chaos=domain.evil) but that was going to be a recipe for pain later, when trying to link to it. I could find ‘all domains associated with the Chaos domain’ still, but trying to write the ID correctly was going to be subject to error if I forgot one of the modified items.
Proposed ID Format: Going back to basic principles: object-type.object-name[/parent-type.parent-name]. I’ll append an encoding of the source document, which is publisher-code:title-code (Core Rulebook is prd:crb), This is awfully close to unique. I’ll capture the object references another way.
Contextually-Aware Parsing
Much of the work in constructing IDs and unique object names was to work around source documents defining objects with the same names and then referring to them. If two books from different publishers each included a spell, ‘frostlight’, they needed to be differenced in the names so they could be differenced in their IDs, and (being spells) added to the spell lists correctly. If one of the books also had a ‘greater frostlight’ spell (“like frostlight except as shown above”), that too needed to be linked correctly. A lot of effort and specific hand-editing went into fixing those.
Then I realized… almost always if there is a name collision like that, any reference to the object by name probably refers to the object in this source document. Next in precedence is the object published by the same publisher. That is, if publisher A has frostlight in Book AA, and publisher B has frostlight and greater frostlight in Book BA, greater frostlight almost certainly refers to frostlight in Book BA, not the one in Book AA. Ditto for the spell lists in each book. If publisher A later publishes Book AC that contains a different greater frostlight or adds a new spell list that includes frostlight, those references are almost certainly aimed at the frostlight in Book AA, not the one in Book BA.
So, the rule for parsing links is:
- If a search string has no match (‘sinper archetype’ is misspelled and will not match anything), give up (probably raise a notice saying “found an unresolvable reference”).
- If a search string has a unique match (‘sniper rogue archetype’ matches only one item), use that.
- If a search string has more than one match (‘sniper archetype’ matches multiple items),
- If there is an object matching that search string in the current source document, use that; else
- If there is an object matching that search string published by the publisher of the current source document, use that; else
- If there is an object matching that search string published in the PRD, use that; else
- If there is an object matching that search string published by Paizo, use that; else
- give up (probably raise a notice saying “found an ambiguous reference”).
A ‘search string’ can be an object name followed by some number of qualifiers, possibly zero. If I have a reference to ‘arcane trickster’ (prestige class, only object with that name), the name alone is sufficient. ‘Fly’, on the other hand, could refer to the skill or the spell, and needs a hint. (In normal body text, non-italic ‘Fly’ will implicitly be treated as the skill, while italicized ‘fly’ will be implicitly be treated as ‘magic’). ‘Sniper’ won’t resolve on its own because there are multiple archetypes of that name, and I expect there is at last one NPC or encounter with that name: it needs a hint. ‘Sniper archetype’ won’t be sufficient either because there is more than one. ‘Sniper fighter archetype’ will resolve, because it is clear which one we want… but in the right place ‘sniper archetype’ has the built-in hint ‘in this book’ or ‘by this publisher’, and thus can be found.
(Sorry for the awkward explanation, I want to get through the thoughts, not polish the explanations…)
This gets slightly more complicated because I have an object taxonomy. I wrote above that ‘fly‘ implicitly gets the hint ‘magic’. In the taxonomy, ‘spell’ is ‘magic’, so that single hint is sufficient, I don’t need to qualify all the types of magic. I could if needed, though: ‘bane‘ could mean the weapon quality or the spell; the hint must be more specific.
What This Means
In changing how objects are defined, and in particular how IDs are created, as long as object-type.object-name is unique in a document I will have a unique object ID. The references to other objects are part of the object definition but are not needed when constructing the object ID; they can be resolved later.
This is a big deal, because in my previous implementation I had to have the object ID definition exact before I could build the index file I use for searching. This is no longer true, because all I need is the object itself and its type (and parent, if any… but that’s defined in the same file, so it’s good).
In changing how the objects are defined, and in particular how IDs are created, I no longer need to be as precise when identifying the relationships. The ‘sniper wood elf ranger archetype’ mentioned above has an ID of ‘archetype.sniper’ (with the source appended), but I can say it is associated with ‘wood elf race’ and that association will now resolve correctly to ‘subrace.wood-elf’.
Re-Implementation
Now for the gory detail, how to build this.
Transformations
The XML workflow is a series of transformations, from ‘document.xml from DOCX file’ through several sets of changes. A personal quirk of mine, I like it when a series of steps has monotonically increasing names. This is partly because it appeals to me aesthetically, but it’s honestly mostly because I no longer have to remember the actual order of transformations, I can tell by the name.
The old series of transformations was
- ‘Clean’, copying document.xml from the DOCX file and stripping all the XML elements and attributes I don’t care about, and some minor restructuring.
- ‘Dename’, replacing text within <w:t> elements I don’t want to see later with other text. Originally called this because the purpose was to remove Product Identity — ‘names’, mostly — from the source content as early as possible. That was so something like ‘Wrath of Irori’ in object names and body text can become ‘Wrath of Anaro’ (helps if the names have similar structure, consonants vs vowels) consistently, so feat lookups and the like get resolved correctly. Also useful for fixing common errors caused by the data capture process, such as ‘spelllike’ and ‘mindaffecting’ losing their hyphens because of how copy and paste from PDF into Word works at line ends… but the original purpose was to fix Product Identity by ‘denaming’. Note that while this can affect document titles and object names, it very specifically does not touch Section 15 information at all.
- ‘Group’, restructuring the large series of document blocks into something more representative of hierarchical document structure. That is, while Word presents ‘Heading 1’, ‘Heading 2’, and ‘Heading 3’ hierarchically in the navigation pane, internally to the file format these are all at the same level. This step restructures them into nested elements: book contains chapter contains section, sort of thing. This also is where much of the object name lines are parsed: “Sniper {fighter {{class” is tokenized into the @name, @mod-refname, and @mod-refdecl attributes… but it does not yet know that it is an archetype (that comes from the declaration, picked up in the next step).
- ‘Normal’, normalizing the content by building the game objects themselves, based on the now-hierarchical content. A <d20:object> can look for a parent <d20:declaration> to find out what type is is and other information. This is where IDs are created by concatenating all the string components together. At this point we don’t have access to the index (no dictionary), so they must be defined precisely. Declarations are discarded at this point because they have served their purpose.
- (‘Index’ file, used for searching in the Parse step below, is created here… must have the IDs before I can make the index.)
- (‘Spreadsheet’ file, a database of objects, their source files, and so on. Built from the Normal files.)
- ‘Parse’, which goes looking for more information, extracting meaning from the content. This includes deciphering prerequisites, resolving explicit and implicit references, and looking for inferred references.
- Explicit reference, string is marked as a ‘reference’ (possibly with hints).
- Implicit references, string is formatted in a way that by convention often marks a reference (most common italics indicating ‘magic’ names such as ‘fireball‘, including complex ones such as ‘potion of cure light wounds‘ or ‘+1 flaming holy greatsword‘). This can probably be expanded for certain fields in stat blocks (such as school, subschools, and descriptors in a spell stat block).
- Inferred references, other text that looks like it could be a reference. Most commonly this means feat, skill, and ability score names (and abbreviations) in body text, but probably not class names or class feature names because they are ubiquitous and often not intended to be references.
- (‘Master’ file containing all content in the data set is created here… must have the parsed objects before making the data file.)
- (‘Nodes’ file containing graph information, built from ‘Master’ file.)
- ‘PreTeX’, which structures the file to prepare for output, including gather content from the data store. For instance, ‘all-classes.docx’ source file has a line that means “fetch all objects whose ID starts with ‘class.'”, which will grab all class objects from the master file.
- ‘TeX’, which is a LaTeX source file to be complied by LaTeX into a PDF.
The new series of transformations is a little different.
- ‘Clean’, as above.
- ‘Dename’, as above.
- ‘Group’, as above.
- ‘Id’, which assembles the object IDs. I’d like to be able to do it as part of the Group step, but this step depends on the declaration-object hierarchy being correct. Does not resolve references; I can know that ‘sniper’ is an archetype that modifies something that is a ‘ranger class’, but don’t need to know what ‘ranger class’ means.
- ‘IdData’ retains all document elements and keeps referencing (modifies, associated with) markers.
- ‘IdKeys’ discards all document elements and referencing markers, but adds search markers.
- ‘Index’ (now in its correct place in the series!), used to resolve links and for searching in later steps. I don’t need to know what ‘ranger class’ is yet, to know that ‘sniper ranger archetype’ is this archetype right here. Built using IdData files.
- While ‘Link’ file below uses ‘Index’ as input, probably only need to rebuild Index when IDs change (new game objects, etc.). Most changes when editing are to document elements or to stat blocks and the like, which won’t affect IDs — which will affect IDs less than they did before.
- ‘Link’, resolving explicit references (including modified and associated object links). Built using IdData files.
- ‘LinkGraph’ to extract all nodes and edges identified by the prerequisites. Old implementation crawls all over the Master file to find objects with prerequisites or that are prerequisites, this would let me capture the details as parsed… this should greatly reduce graph building in future, since most of these don’t change between builds.
- ‘LinkText’, looking for implied references (as ‘Parse’, above). May include parsing stat blocks and the like.
- ‘Lookup’, feeding into a relational database to make object queries — looking up objects with various characteristics — easier. At least, I find SQL easy, compared to arbitrary XSLT to find objects, especially when I can store the queries.
- ‘Master’ (now in its correct place in the series!), as above. Uses LookupData, doesn’t need to pull in all the bits I don’t care about here.
- ‘Package’, as ‘PreTeX’ above: use the LookupContent file as input, copy from the Master file as required. I’ll be adding more output options, so it’s no longer just ‘pre-TeX’.
- (output options happen here, don’t know the names yet… but I expect to branch for TeX, Word, and HTML at least)
The big changes are
- I greatly simplify ID construction. Previously I had all sorts of interactions and logic branches, now it’s just “what is this object’s base ID, append parent base ID if needed, append source marker”. Much, much simpler.
- Search criteria are no more difficult than before.
- Resolve modified/associated object references later. These references no longer need to be quite as precise because I can use the full search engine.
- Can now have multiple references of a type: a subdomain can now properly connect to more than one domain, an archetype can connect to more than one class and/or more than one race, etc.
- Should significantly reduce Master build time by ignoring document elements I don’t need.
- Should not increase build time of Package file because the source file should not include instructions to copy from itself — prd-core.docx defines the Alertness feat, and thus does not need to copy it; where it copies the Extra Channeling feat (which was updated in a later source) it’s copying from another file.
Next Steps
What do I need to do from here?
- Refactor some more code:
- Move object definition from docx-normal.xsl to docx-id.xsl.
- This includes removing now-unneeded ID construction code.
- This includes separating IdContent and IdData (share ID construction, but differ on how document elements are handled and the creation of search details).
- Revise docx-index.xsl to build context-aware search support.
- Move text parsing from docx-parse.xsl into multiple sources
- docx-link.xsl (common across data sets)
- docx-link-base.xsl (core search functionality, used by docx-link.xsl and docx-lookup-*.xsl)
- docx-lookup-content-<dataset>.xsl (dataset-specific parsing rules, for all text)
- docx-lookup-data-<dataset>.xsl (dataset-specific parsing rules, discarding unneeded document elements)
- Move data dump from ‘docx-spreadsheet.xsl’ to ‘docx-list.xsl’. Needs to be new tables, the old ones won’t work because of the changes to how relationships are encoded.
- Revise docx-master.xsl to use *.lookup-data.wml files instead of *.parse.wml files.
- Move text and object selection/arrangement code from docx-pretex.xsl to docx-package.xsl. Should be possible to make consistent across datasets (draw from different Master files, but otherwise same processes and procedures).
- Revise graph construction.
- Move node and edge detection from docx-nodes.xsl to docx-link-graph.xsl
- Revise docx-nodes.xsl to build Nodes file from LinkGraph files — aggregate graph information in a way similar to building Index files, then examine nodes and edges to generate output. Because all nodes in the file are on side or the other of an edge, can safely assume all nodes in the file represent a specific object joined to other objects. Some graphs may become single-node if all connections would get folded into one node or the other, as can happen with skills or scores.
- May need to adjust docx-pics.xsl if output of docx-nodes.xsl changes.
- Move document construction code from docx-pretex.xsl to docx-package.xsl.
- Much will work the same, but consider reducing file size by doing Section 15 better. Make two passes, one to gather objects and one to gather Section 15, then unique and sort so there is one copy for the entire output document, instead of multiple copies that later need to be cleaned up. (Might instead mark intermediate objects with the ultimate ancestor containing Section 15 plus any other Section 15 that should be picked up, then make a pass through the intermediate objects to tidy this up… not sure.)
- Move object definition from docx-normal.xsl to docx-id.xsl.
- Remediate data. There’s no way this won’t cause or uncover problems.
- (probably) fix manually-differences references, either because they are no longer needed or because they’re busted.
- Create docx-pub-tex-*.xsl, encoding of document and game elements is undoubtedly changing. These will probably incorporate code from existing docx-tex-*.xsl, but I know I want to refactor this somewhat also.
- Create docx-pub-word-*.xsl, I don’t currently have an output mechanism for Word files.
- Create docx-pub-html-*.xsl, I don’t currently have an output mechanism for HTML files.
Closing Comments
There is more to do here than I’d hoped. Less than I’d feared.
That could change. I felt places I could rabbithole so hard I’ll wave at Alice as I go shooting past her.
Congrats on the refactored process. I hope this removes the special case coding.
As someone that as been working in a high-need area during the pandemic, I relate to the feeling of ‘finally I can work on this’.
I believe it will remove the special cases. It is slightly more work to set up, but once it’s in place all the cases I’m looking at should work the same way (just some have one, some have several… but for-each solves everything!).