Yesterday I decided it’s finally time to dive into Seventh Sanctum data files. They are a little more complicated than I expected, but that’s okay. As I dig further, I see ideas that never occurred to me in my own random generators.
This feels very much like an evolved system rather than a designed system. Fair enough, I see some intriguing ideas here that I can’t imagine someone thinking up first. This looks like something that came from someone who ran into roadblocks with his tools… and found ways around them.
I appreciate the hell out of that mindset!
File Types
I see primary file types here (plus a README.txt.txt, which I’ll ignore in this count).
- Configuration files that define what vocabulary files to load for processing different subjects. For instance, there is a
pizzaconfdat.txtfile that shows what files to load to generate meat pizzas, vegetarian pizzas, mixed pizzas, or all options. I imagine these are used by the website to let the user identify the subset of the generator to apply. - Vocabulary files that are relatively simple random text generators. I say ‘relatively’ because there are some little twists here that I would not have imagined. Syntactically it’s not very complex, but the interactions are subtly complex.
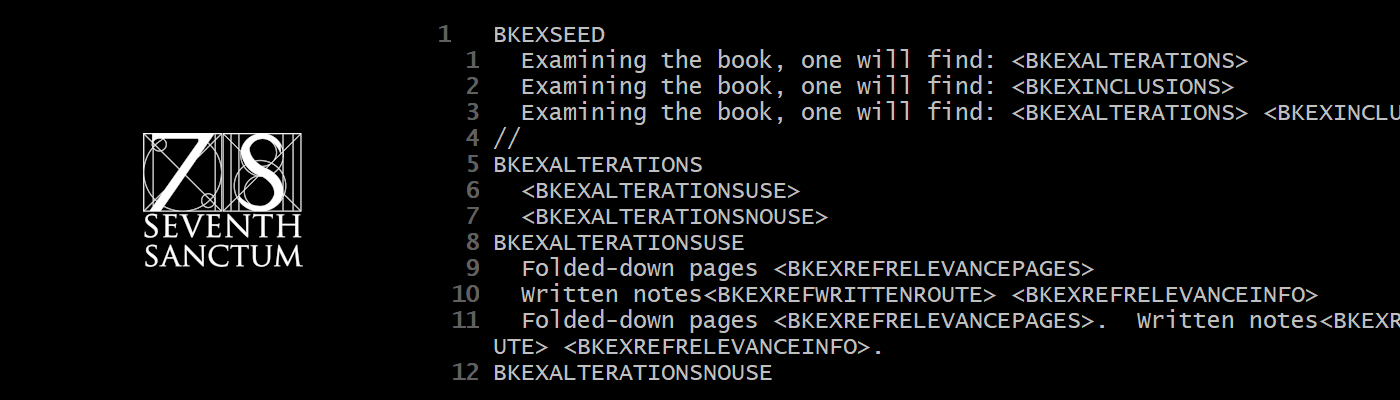
- Seed files, so named because they each (except one, I think) start with a root object called ‘SEED’. These are markedly more complex text generators than the vocabulary files. It was something of an epiphany when I realized that what I thought were variables were actually dynamic tables. That is, there were some entities here I thought were variables, then discovered were subtables… and then, that they can be concatenated.
Parsing the files mostly is not difficult. Applying what I’ve parsed will be a little more challenging.
I’m here for it.
Comparing to Imagination Helper 1.0
In the late 1900s (very late, 1997 or 1998) I wrote a random table program. The file syntax was inspired by a program I found online called ‘BNF’. BNF was almost the opposite of a parser: it took a file of BNF-like text, and randomly selected options until end points were reached.
My program worked in much the same way, with an extended syntax. I added certain functions, abused table definitions to act like functions, and a few other things. I’m pretty proud of it and have been using it for a quarter century.
It can’t do some of the things Steven Savage did with Seventh Sanctum.
- I don’t quite have the concept of the configuration files. My tool was intended for command line use, so I never needed the ability to ‘define’ or ‘discover’ entry points.
- My dictionary files are closest to vocabulary files, but they don’t classify string types. I can convert almost all the vocabulary files into dictionary files.
- And then I found one that wants to pick strings from two tables that are not explicitly combined.
- The files can be split, so the three sections are each in different files. In the pizza example, the template strings for the ‘menu’ is stored separately from the ingredients file.
- I had expected the seed files were just more complicated versions of the vocabulary files. Then I found a comment in one of them that explained what certain markup meant. Turns out the file does not contain tables, quite, but the pieces needed to make tables. My dictionary files contain just tables, and I don’t yet have a way to do what the seed files do.
So, my original plan to translate Seventh Sanctum files into my random text generator isn’t quite achievable. Bummer.
I have an opportunity to make my random text generator more powerful!
Now, the question is… do I go back to the C++ code and change that? Or implement in another, more modern language?