

Yesterday I explored some data objects I expect to need in my media library. That’s a good start, but a relational database is not particularly useful until it has relationships.
Thus, I’ll want an Entity Relationship (ER) Diagram showing how the different pieces are related.
In this post I’ll also look at various scenarios relating to the objects being tracked, to see if the model can support the various situations I expect to encounter.
ER Diagram
In the diagram below, I use different colors to represent tables containing different types of information.
- White nodes are entities.
- Yellow nodes are associative entities (‘link tables’ joining two or more tables, often used for many:many relationships; convention at my work is to append ‘_xm’ to the table name).
- Green nodes are used internally by the engine and by plugins, and are not ‘actual data’ (i.e. not part of the business domain).
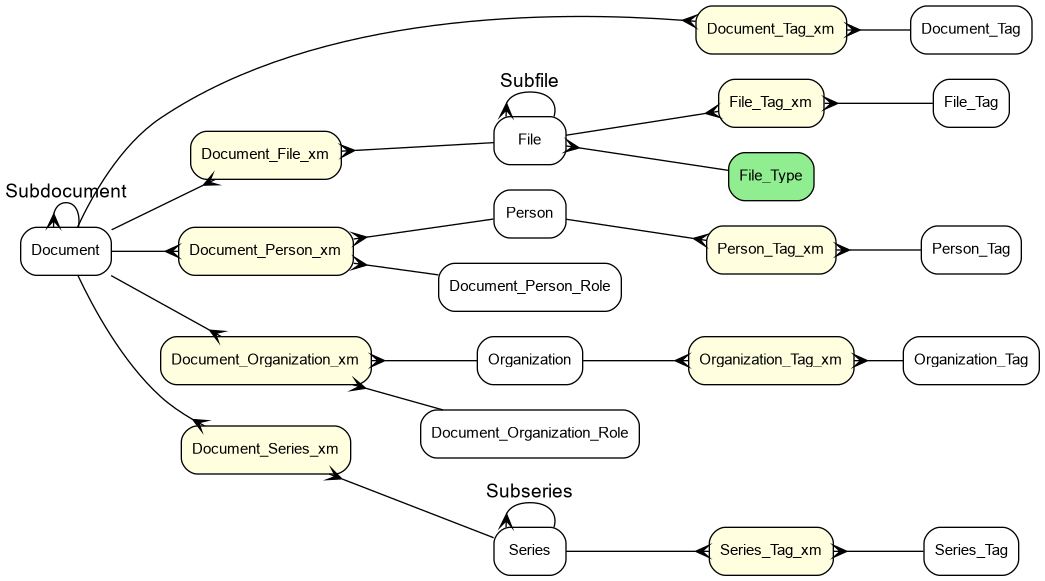
Some other notes about the tables in this diagram:
- Entity tables will use surrogate keys (I often like to use business keys, but this data has no natural business keys).
- XM tables likely use their foreign keys as composite keys. For instance, Document_Person_xm probably has (document_fk, person_fk, person_role_fk) as a primary key.
Evaluation
To see if this model will meet my needs, I’ll see how various scenarios would appear in the data. These are possible approaches, some scenarios may have multiple feasible approaches.
- Book with a single author, single edition, single file:
- Document record for the book.
- Person record for the author.
- Document_Person_xm record connecting the Document and Person records, with the Document_Person_Role identifying that the person was the ‘Author’.
- File record containing the ebook data.
- Document_File_xm record connecting the Document and File records.
- Organization record for the publisher.
- Document_Organization_xm record connecting the Document and Organization records, with the Document_Organization_Role identifying that the organization was the ‘Publisher’.
- Book with multiple authors:
- As above, but with more than one linked Person record.
- Book with fully-detailed development team:
- As first, but with many Person records and different roles… a single person may have more than one role working on the book.
- Pathfinder Core Rulebook (downloaded ‘one file’ and ‘one file per chapter’):
- One Document record for the book.
- Creator list (Person & Document_Person) records probably hang off this Document record.
- File for the document as a whole.
- One Document record (subdocument) for each chapter.
- One File record for the subdocument.
- One Document record for the book.
- Pathfinder Core Rulebook (as above), with errata:
- As Pathfinder Core Rulebook above, adding a subdocument for the errata (with associated File).
- … this suggests ‘subdocument’ might want a role or similar.
- Technical book (ebook & ZIP file containing source code):
- One Document record, with metadata (creator list, publisher, etc.)
- Two File records, one for ebook and one for source code?
- One File record per file (i.e. one per subdocument).
- Magazine with many articles by different authors:
- One Document record per issue, some metadata (publisher for sure, magazine staff who work on the article as a whole, etc.) goes here.
- Subdocument per article, with metadata (author, etc.) per subdocument.
- File for the magazine issue.
- No files for the subdocuments.
- ZIP file containing stock art (three images and a license):
- One Document record for the ZIP file, with associated metadata.
- One subdocument record for the license (with ‘license’ role?)
- One subdocument record for each image in the ZIP file (possibly with image metadata: size, color depth, tags about content, etc. — ‘image’ file type/plugin might handle this).
- Video file, in multiple resolutions/formats:
- One Document record for the video.
- One File record per file, with video file metadata showing different resolutions, formats, etc.
- Anime series, one season:
- Series record for the series.
- One Document record per episode.
- One or more File records per episode (if there are multiple resolutions, or if OP-Content-ED are separated — same OP/ED files could be used in multiple Documents)
- Anime series, multiple seasons:
- As ‘Anime series, one season’, but probably with a subseries for each season… especially if the seasons are named differently (Monogatari, I’m looking at you).
- Anime series, via multiple fansub groups:
- One Document record per episode.
- Series record for the series as a whole. Could have subseries for different seasons, especially if they’re named differently (Monogatari, I’m looking at you).
- One subdocument record per episode/fansub group (because organization information is associated with the Document, not the File… by default, at least, since someone could add ‘Fansub group’ to the File if they want).
- One or more File records per episode (as above).
I can come up with more examples, but they mostly would be encoded as above. The models above are probably pretty close to how I would encode the content of each scenario, but the last one is pretty funky. S01E04 of My Favorite Anime is the same episode, fundamentally the same ‘document’, but the different fansub groups could have different translations (Demon City Shinjuku has different character names depending on who did the translation, and those were ‘professional’ translations).
Changes Coming out of Evaluation
Not many, it looks like the original approach will probably be feasible. However, there are a few things I’ll want to explore.
- Subdocuments look like they could have a ‘role’. For instance, if you have a document made of multiple pieces (one file per chapter) you might just say they are pieces (and probably want to order them). Errata could reasonably be a subdocument of the document it is amending. Web enhancements are similar. Other documents could have supplementary material.
- Tags might get collapsed to a single table, if they are simple attributes.
- I didn’t really touch on languages, but it’s reasonable that a document could be present in multiple languages… perhaps that might fit better on the File? A thing to be explored.
“I didn’t really touch on languages, but it’s reasonable that a document could be present in multiple languages… perhaps that might fit better on the File? A thing to be explored.”
This is certain. You will have audio tracks and subtitles in multiple languages.
Of course. I hadn’t thought about that specifically, but of course that’s a thing. For that matter, a single anime video might have audio tracks in multiple languages, subtitles in multiple languages, and even the same language covered multiple ways (all vocals subtitled, only songs, subtitles for written, different translations to the same language, and so on). I’ll want to think about how this could best be modeled.
I don’t think in a single model I’ll want to have language on more than one entity type. For books it might make sense to put it on the document, but for anime it might make more sense to put it on the file — “S01E04 has a 480p version with Japanese and English audio/dub, but Japanese, English, French, Spanish, German, and Russian subtitles… and a 1080p release that has only Japanese audio but Japanese and English subtitles”. These could be treated as the same document but different files.
I have the sense that the model I’ve got so far will have a great deal of flexibility in application.