Of the Seventh Sanctum files, the configuration files I described yesterday are the simplest.
They were not, however, the first files I dove into. The seed files looked the most complex, but the vocabulary files looked immediately useful and easy enough to start.
So that is where I started.
Sections
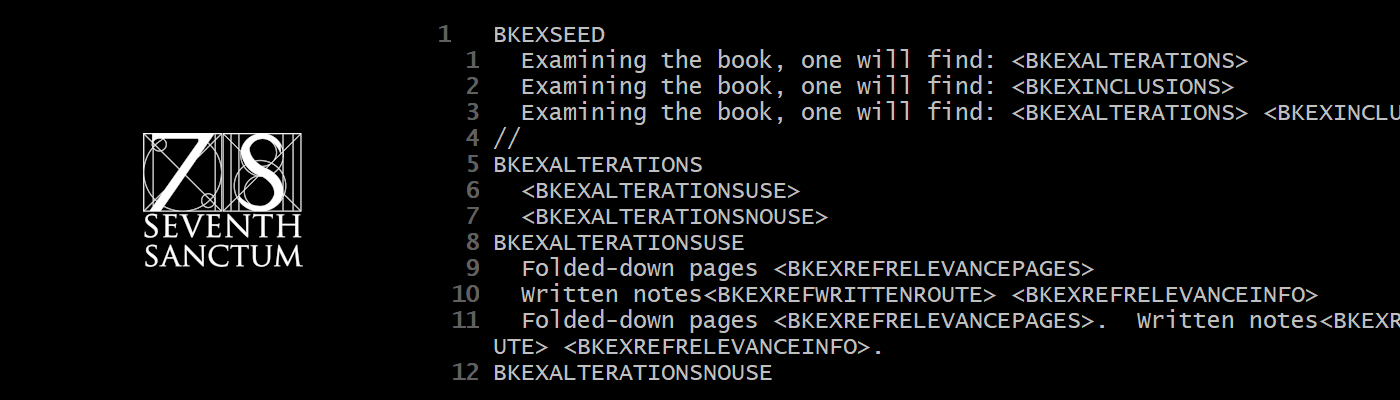
Vocabulary files have three sections. One is totally optional and in fact is not often used. The other two both are needed for string generation, but they do not need to be in the same file. There also is a fourth ‘semi-section’: it’s all commented out, but is important for understanding a particular word set.
Types Section
This section exists solely for the reader and person editing the file. It consists of several lines of comments at the start of the file identifying ‘type flags’ attached to words.
// Types
// 1 - Cheese
// 2 - Meat Topping
// 4 - Vegetable Topping
// 8 - Spice
// 16 - Sauce
// 32 - CrustThis segment is for human consumption and isn’t always consistent. I’ve seen it without the hyphens, or with number and meaning reversed, and so on. Useful, not strictly needed by the engine because it looks only at the numbers.
Which, if you’re a programmer, you recognize as being powers of 2. These are used to identify words in different sets. More on that in ‘Vocabulary Section’ below.
Organization Section
This section provides templates for choosing words and putting them into output strings. It consists of a heading, then what I’ll call ‘choice’ and ‘picture’ rows.
--ORGANIZATION
2,1
, and ,
2,4,32,1
, and , on ,<COMMA> with extra ,The first line marks that we’re going into the organization section. The three lines starting with ‘2’ say what string sets to draw from. The three lines starting with commas (‘,’) give a picture of the output line, with each comma replaced by a string from the previous line. If you need an actual comma in the output, use <COMMA>. If you want to weight the results, use multiple copies of the same (choice, picture) pair.
When rendered, the engine
- randomly picks a (choice, picture) pair,
- picks words from the indicated sets,
- places the words in the picture.
Above, the (choice, picture) pairs would generate something like
- pepperoni and mozzarella
- ham and olives on thin crust, with extra feta
Seems simple, right?
Well, it seems simple. The numbers above don’t have to be powers of 2, you can mask multiple values together. An ‘anything’ pizza with extra cheese can be written as
6,6,6
,<COMMA> ,<COMMA>, and ,<COMMA>, with extra ,This can give us
- olives, ham, and pineapple, with extra provolone
- ham, ham, and ham, with extra cheddar
I don’t think I’d want either of those, but I don’t judge.
Vocabulary Section
This section lists all the words to be considered for selection, and what types they are in. There is an optional element to this section that I’ll explain later, after I describe the categories section.
--VOCABULARY
mozzarella,1
cheddar,1
feta,1
pepperoni,2
ham,2
sausage,2
pineapple,4
onion,4
olives,4
chili flake,8
basil,8
tomato sauce,16
bolognese sauce,16
barbecue sauce,16
thin crust,32
stuffed crust,32
gluten-free crust,32… downside of my example data set, I don’t have any words (toppings, etc.) that fit into more than one type.
If I were working with colors, though…
//Types
// Metal - 1
// Gem - 2
// Red - 16
// Green - 32
// Blue - 64
// Yellow - 128
// Orange - 256
// Purple - 512
// Black - 1024
// White - 2048
// Brown - 4096
--VOCABULARY
yellow,128
lemon,128
citrine,130
gold,129
red,16
ruby,18
green,32
cyan,96
turquoise,34
copper,4301If I want to see ‘green colors’, I mask the type values above with 32: green, cyan, and turquoise. ‘Copper’ can be considered a metal color, or a red, orange, or brown, or even green (verdigris — oxidized). It’s weird, but works for my example :)
Categories Section
This section is optional, and appears to be infrequently used. Still, it is in some of the files and has a purpose, so let’s go.
As best I can tell, the purpose of the categories section is to avoid ‘Moon Moon’. Or as shown in the eranamegendat.txt file, ‘Angelic Era of Angels’. If I understand correctly, you are not allowed to have two words with the same category in the same output.
As with the other sections, there is a heading row and then the content. I’m going to have to change examples here, since I can’t come up with good
--CATEGORIES
Moral Alignment
ALIGNMENTMORAL
Ethical Alignment
ALIGNMENTETHICAL
--VOCABULARY
good,1:alignmentmoral
evil,1:alignmentmoral
lawful,1:alignmentethical
chaotic,1:alignmentethicalHere, you can have ‘lawful’ or ‘chaotic’, or neither, but not both. And you can have ‘good’ or ‘evil’, or neither, but not both. This gives the potential of having any of the nine alignments, but no ‘lawful lawful’ or ‘lawful chaotic’.
I think I can see how to use this so you don’t have opposing values. If you have a prefix string of ‘diabolical’, you might want to avoid ‘redemption’.
(Actually, I would want to see that, ‘diabolical redemption’ sounds badass to me. But for the sake of my example, let’s continue.)
I would have the prefixes and suffixes in different types, then have crossed categories. That is,
//Types
// 16 - prefix
// 32 - suffix
--ORGANIZATION
16,32
, ,
--CATEGORIES
Evil
EVIL
Good
GOOD
--VOCABULARY
angelic,16:good
diabolical,16:evil
redemption,32:evil
justice,32:evil
vengeance,32:good
temptation,32:good
knowledge,32
war,32(I jumped ahead, I expected to have another section in this page about the category-aware vocabulary… well, there it is. When a vocabulary entry has a category, append a comma-separated list after a colon after the type. )
This seems backward, but if the categories work as I think, this prevents conflicting pairs. That is, within the limits of our data here, you can get
- angelic redemption
- angelic justice
- angelic knowledge
- angelic war
- diabolical vengeance
- diabolical temptation
- diabolical knowledge
- diabolical war
You can’t get ‘angelic diabolical’ though, because there is no (choice, picture) pair that includes type 16 twice.
Actually, I assume you can have a mix of categorized and non-categorized vocabulary. All the files I’ve looked at have either all or none categorized.
Loading Multiple Files
As I said above, it is not necessary to have all sections in the same file. Only the organization and vocabulary sections are mandatory, and then only by the time you start using the data. In the pizza example above, all the ingredients are in pizzadat.txt, suitably encoded. The pizzameatdat.txt, pizzavegdat.txt, and pizzamixdat.txt files each contain only the organization sections for the indicated types of pizza. As the files get loaded, the organizations get aggregated into the final set of rules.
Similarly, you can have vocabulary sections loaded from multiple source files. I don’t remember seeing that in practice, though. I can imagine a set of ‘color vocabularies’ that have ‘simple colors’ and ‘fancy colors’ (the basic color wheel vs. paint catalogs) that get loaded and used with the same organization section.