
Most of the work done on my XML Workflow has focused on process content from Word files via XML. Word is probably the most useful format by volume, because of the amount of text in varying structure. However, it’s not the only format that is of use to me.
Excel workbooks can be a very useful container for simply-structured (record-based) data. The dename input file, for example, consists entirely of (old name, new name) tuples. Formatting overrides are (object identifier, override instruction) tuples. I can move both of these to Excel workbooks and save myself a great deal of trouble.
New Stages
There are several new stages in my workflow, specific to handling Excel workbooks as input. The ‘common’ stages are part of every data flow, the ‘specific’ stages produce files for specific purpose.
Book (Common)
This stage is comparable to the Base stage in the Word workflow, except it uses my workbook app. Excel workbooks encode the spreadsheet XML file in a way I don’t want to deal with. I’m going to side step and just have this app push out a Workbook XML file. This file has all the content of the Workbook, as with the Base file from Word.
Bundle (Common)
The Bundle file is more or less comparable to the Clean stage in the Word workflow. All Excel Workbook XML is stripped, and I’m left with an element for each tab. Each non-empty row is presented as a child element, with fields based on column headers.
This allows me to store arbitrary record-based data in the source Excel workbook. There are really only two constraints.
- Bottom-row column headings must be valid XML attribute names.
- No duplicate bottom-row column names.
I can have
- Column headings above the bottom row that are not used as field names.
- Columns without bottom-row headings (but possibly higher-row headings) that are not treated as fields.
- Formulas and calculated fields — the Bundle stage care about the text of the cells, not how it got there.
- Worksheets (tabs) with different data sets.
Downstream scripts will need to know what to expect, so they can parse the information correctly. This is still much simpler than parsing apart Word content.
Byname (Specific)
This stage produces a file of string substitutions to use in the Dename stage. The key fields of each tuple are (original, replacement). Any time the ‘original’ string is found in text, replace it with ‘replacement’.
Records from almost all tabs are included. I expect to break up the input file to keep each worksheet a reasonable size, or group related information. I expect also to have a tab for lookup tables and the like.
ModPic (Specific)
This stage produces a file common to the entire data set, or perhaps to a single domain. The automated conversion of DOT diagrams to TikZ diagrams works quite well overall, but sometimes it can use some help. For example, row separation in the diagrams defaults to a distance that should minimize overlaps. When the nodes are single line, this can look too empty. In the ModPic file I can mark that diagram to have a tighter row separation. I can also mark that several diagrams are substantively the same, so use a single diagram for all of them.
The tuples of this file are (diagram identifier, override instructions). I expect to have a separate worksheet for each domain… or I can have a separate file for each domain. Regardless, I will have only a single set of overrides to be applied across all diagrams. The diagrams are, after all, independent of the document they are included in.
Override (Specific)
This will likely replace the d20:override elements in the Word source files. Right now overrides are stored in the output Word file. This leads to recompiling source documents and the master data store, when all I want is a formatting change. This is inefficient (read: annoyingly time-consuming). Moving the overrides out of the Word file into an associated file can be much better.
Tuples here would be (object identification, override instruction). I expect I would have a tab for each build configuration. For example, ‘PRD Final’ and ‘PRD RAF’ have the same objects but different content for each. They would share some interventions but have others that are specific to that domain and build.
Integrating with Make System
I use GNU make as my build manager. While on vacation I discovered how to give targets ‘optional requirements’. That is, “if this file can be created it must be created and current, but if it can’t, no problem”.
The Byname file is used across the system, for all domains and builds. I expect to have pf1-bynames.byname.wml, much as I have pf1-taxonomy.helper.wml. My older Makefile rules can deal with this situation.
An Override file applies to a single target title (input file leading to all required domains and builds). Any source Word document can have an associated Excel workbook with override information. That is, prd-tech-guide.docx can have prd-tech-guide.xlsx that becomes prd-tech-guide.override.wml. However it doesn’t need to have prd-tech-guide.override.wml and will be just fine if prd-tech-guide.xlsx doesn’t exist.
Updated Workflow Diagram
This thing keeps getting bigger and bigger… but I don’t see any stages I want to remove.
One new element of the workflow diagram: ‘referenced files’. The nodes with thick dashed borders let me mark a relationship between stages that are far apart in the workflow. For example, ModPic and Override at the top both feed into Package… but Package is at the bottom. There is no good way to draw edges between them, so I don’t. Instead, I add a proxy for ‘Package’ so I can show the relationship to a node elsewhere in the workflow.
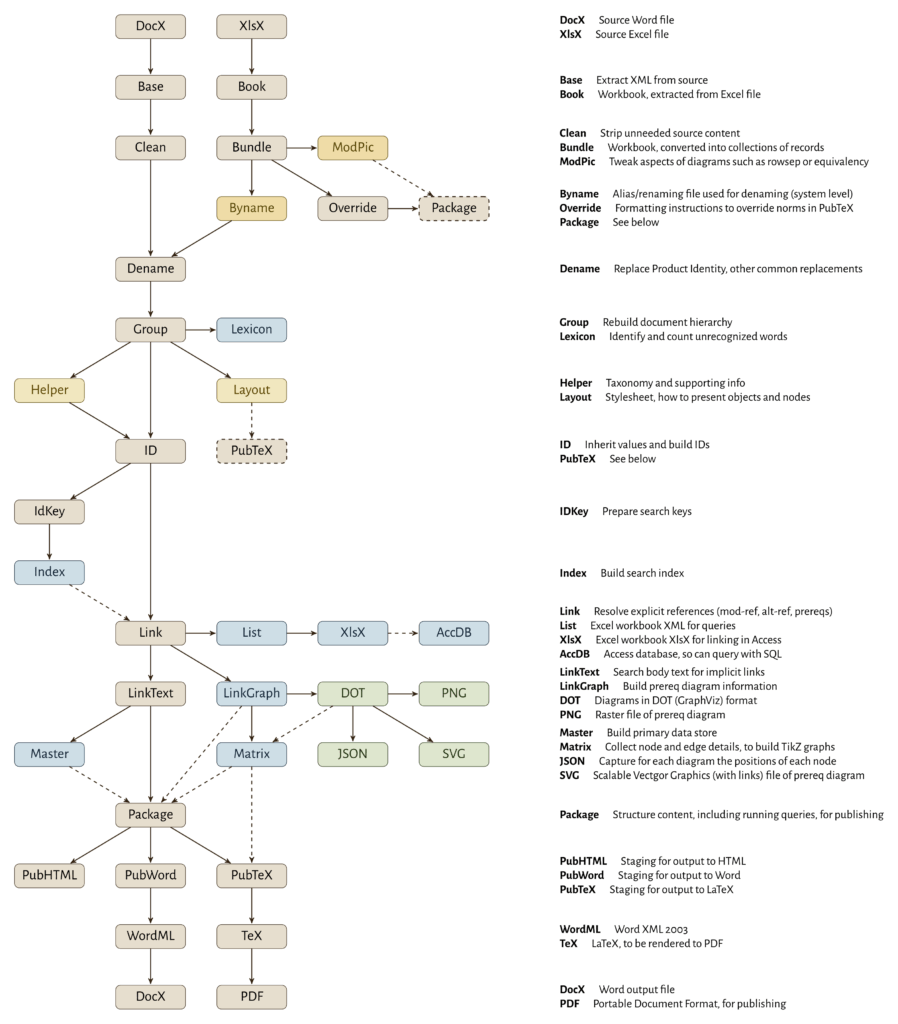
I’ve updated the legend as well, to show the new node type.

Very interesting read! I like how the article explains using an XML workflow as a new and efficient method — especially for streamlining data exchange and content management. Thanks for sharing this fresh perspective.