Over the last year I’ve been reworking my data engine, and I’ve reached a point where it’s actually useful again. It’s not finished, but I am least up to the point of being able to identify object prerequisites and search for objects in text (such as feat names).
One of the benefits I hope to gain is to improve resolution of name collisions. There are several scenarios that come up.
Search Strings
In building my index, I create several search strings for each object. These search strings are based on a concatenation of the following factors:
- Name
- plus aliases (‘armor class’ also is ‘AC’, etc.)
- plus plurals of name and aliases, sometimes (‘wishes‘ shows up quite a bit, and ‘arrows’ and ‘goblins’… but I don’t remember seeing ‘Alertnesses’; not all types have plural names)
- Parent, if this object is child of another object, such as a class feature being in a class or archetype, or a granted power in a domain.
- Alternate (another associated object, such as a race for an archetype that applies to characters of a particular race — subraces use ‘modified’)
- Modified (the object this modifiers, if this is an archetype or similar)
- Type (which I refer to in code as ‘decl’, for declaration, because ‘types’ are a game thing — feat types, etc.)
- Types also can be aliased: there are special abilities that are sometimes referred to as ‘special attack’ or ‘aura’
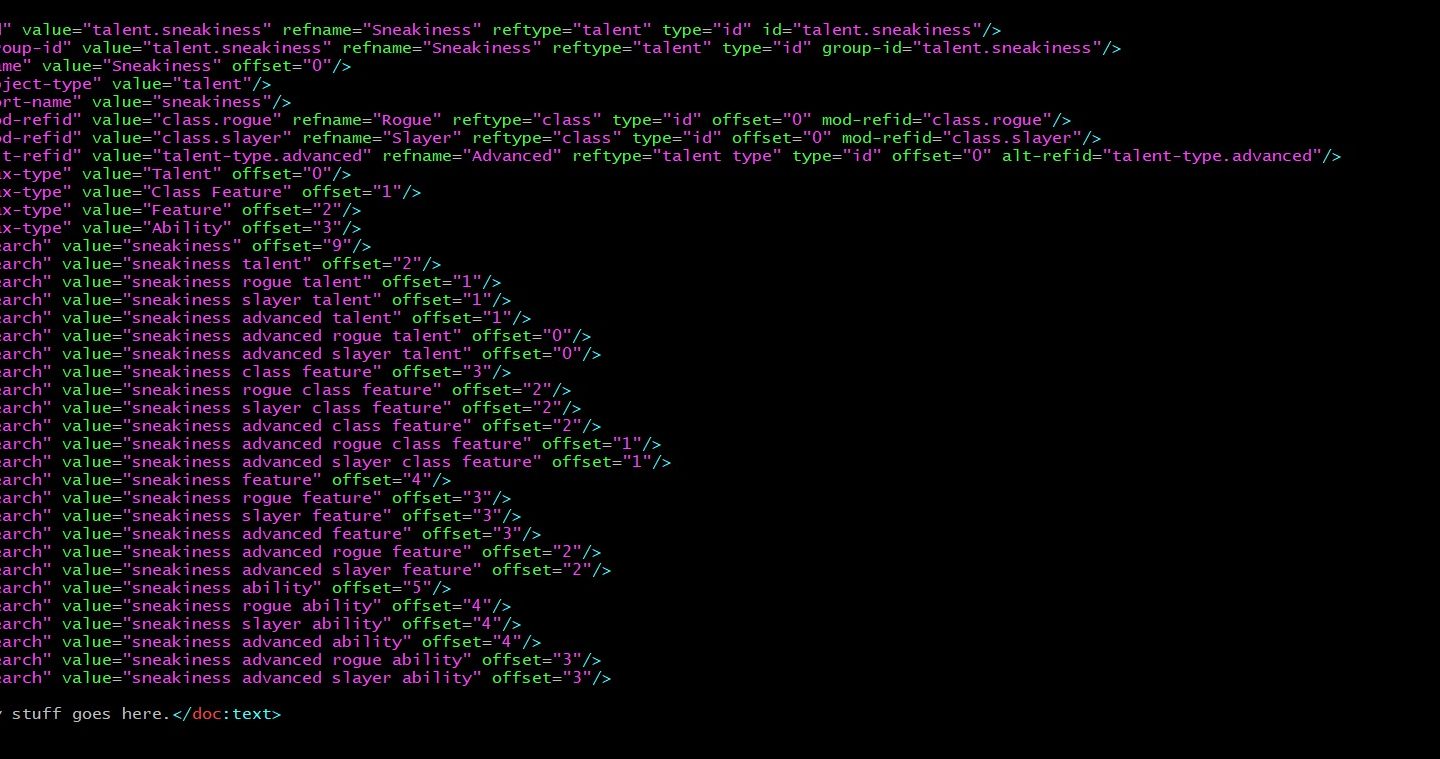
The only mandatory object is the name/alias/plural. Everything else can be present or not. For instance, the Alertness feat has the following search strings:
- alertness feat [offset 0]
- alertness ability [offset 1]
- alertness [offset 9]
Each search string has an ‘offset’ indicating how good the match likely is. This will be used later for tiebreaking. I’ve always used ‘9’ for the naked name because I only want that to be picked if it is a unique match, and 9 is higher than any calculated offset. I didn’t calculate a ‘true offset’ because I didn’t want one to take precedence over another simply because it has a shorter taxonomy.
A more complex example, the forgemaster cleric archetype has the following search strings:
- forgemaster dwarf cleric archetype [offset 0]
- forgemaster dwarf archetype [offset 1]
- forgemaster cleric archetype [offset 1]
- forgemaster archetype [offset 2]
- forgemaster [offset 9]
For child objects (class features in a class or archetype, granted powers in a domain, etc.) it gets even more. The artificer feature of the forgemaster archetype has the following search strings:
- artificer forgemaster class feature [offset 0]
- forgemaster artificer class feature [offset 0]
- artificer class feature [offset 1]
- artificer forgemaster feature [offset 1]
- forgemaster artificer feature [offset 1]
- artificer feature [offset 2]
- artificer forgemaster ability [offset 2]
- artificer ability [offset 3]
- artificer [offset 9]
Object aliases (aka and plural), and taxonomy declaration aliases, get a slight bump to the offset. The fireball spell, for example, has these search strings:
- fireball spell [offset 0]
- fireballs spell [offset 0.1]
- fireball magic [offset 1]
- fireballs magic [offset 1.1]
- fireball [offset 9]
- fireballs [offset 9.1]
This seems a little overdone, but I’ve found that while not every search string actually will be used, I’ve seen almost all of these permutations used in practice.
Creating the Index
Building the index loads all the source files and looks at all the search strings for all objects.
For each unique search string I create a ‘key’ with that search string. All searches will start with these strings (that is, I might look for ‘alertness feat’).
Each key has ‘matches’ within it that identifies a single matching object and how that object matches. The match has an ‘offset’ indicating how close the string matches the object, plus a bunch of ‘hints’ that can be used to refine the results. These hints include:
- Taxonomy values to let me refine the search, going from generic to more specific results. For instance, searching for ‘bane magic’ will find the spell and the weapon quality, but if I give a hint of ‘spell’ or ‘weapon quality’ it will augment the default search.
- Referenced objects (parent, modified, alternate). If I look for ‘sneak attack class feature’ I’ll find lots of them, all on different classes, but if I add ‘rogue’ as a hint it will find that one specifically (not needed for ‘sneak attack rogue class feature’, since that is a unique match, but I can add a hint to a search string without having the reframe the search string).
- Publisher code (PRD for the Pathfinder Reference Document, PZO for other Paizo products, EGD for my own imprint, and so on).
- Source code (short string identifying the specific source, used mostly implicitly to look for the ‘one of these in this book’).
- Explicit hints added by the taxonomy or the object direction. For instance, the mythic feat and mythic spell taxonomy entries explicitly add the ‘mythic’ hint.
- A ‘taxonomy path’ listing the taxonomy entries from root to the leaf for this object. For instance, ‘ability;feat’ or ‘ability;feature;class feature’.
I group the results by group-id (which has the form ‘type.name’ — ‘feat.alertness’, ‘archetype.forgemaster’, ‘class-feature.sneak-attack’) and check also for any that are ‘only child objects’. For instance, in the PRD data set ‘sneak attack class feature’ always resolves to a feature of a class or archetype, as might be expected. They all will end up with the same precedence in my matching, so I cannot resolve ‘sneak attack class feature’ to a specific object. To fix this, I synthesize a ‘stub object’ that otherwise looks like a ‘naked class feature’: a class feature outside a class or archetype. I do the same with granted powers, revelations, and so on. However, I do this only when the group has more than one object: the artificer class feature is found only in the forgemaster archetype, so I won’t need to resolve any conflicts. (It would harm nothing to add it anyway, but I found it confusing when I looked at the file — the single match was an exact match of a child object, and the synthesized object had an offset of ‘-1’, which made me feel weird.)
Doing a Search
Now we get to the core of the whole thing, where we actually search. I’ve created a centralized search routine that will take a string plus associated hints (including a context node I can use to figure out what source I’m coming from) and tries to run down a single matching object. Because of the interdependencies between things and variability in what can actually apply, I can’t easily make an XPath expression that will do what I need, I’ll need to winnow down the results iteratively.
The search function takes the following parameters:
- A context node (used to find the source I’m coming from, which might be used in resolving duplicates).
- Name of the object to search for. Might actually be a full search string, but that’s okay.
- Decl (type) of the object to search for. Might be blank if the name contains the whole search string, or if I’m doing a naked name search.
- Index (data structure to search — contents of the index file).
- Hint, a supplementary clue as to what I’m looking for.
The search routine then starts hunting.
- Look for the string matching ‘$name $decl’. For instance, if I pass in (‘Alertness’, ‘feat’) it will look for ‘alertness feat’).
- If this doesn’t find any matching keys, we’re done. This happens quite a bit with prerequisites: many do map to objects (and there is a fair bit of variability in how the searches are done to make this so), but there are also quite a few weird ones, such as “must be at least 100 years old”, that just aren’t going to match anything.
- If the above finds a matching key, filter by $hint (if none of the matching objects fits the $hint I don’t want it — if I hint the Alertness feat I’m looking for is ‘mythic’ and all I find is the regular one, I don’t want it).
- Examine the results so far and find the ones with the lowest offset.
- If there is only one with the lowest value and the taxdecl-path value of that is a the start of all taxdecl-path values for the objects in that set, use that. For instance, ‘alertness feat’ finds two objects, one is the feat (‘ability;feat’) and the other is the mythic feat (‘ability;feat;mythic feat’). The Alertness feat has the lower offset and both taxdecl-paths start the same, so the feat is deemed correct.
- If there are more than one with the lowest offset or the taxdecl-path value is not the start of all taxdecl-path values for the objects in that set, search for objects fitting certain combinations of hints, in decreasing order: (source, publisher), (publisher), (‘prd’), (‘pzo’). That is, look first to see if there is a matching object in this source, then from this publisher, then from the PRD, then from Paizo. If I reach a point where “one with the lowest value offset, and all taxdecl-path start with that one’s taxdecl-path” is true, I’m done.
This should let me largely drop the manual differencing of names. If two different sources add spells of the same name, and they are added to spell lists in those sources, the references should resolve to the spells in those books. Ditto for implied references (spell name in italics, prerequisites referring to feats in the same book, etc.). I might still want to take steps in presenting the links in my books, but I should no longer have to manually difference them in the object names and in body text to make sure they connect.
Closing Comments
This was a fair bit more long-winded than I expected, but it helped me hash out in my mind how the code has to work.
It does not particularly surprise me that the resulting code will be considerably smaller than the code I had in the previous iteration, full of special cases and conditions (which was in turn quite a bit smaller than the iteration before that). The difference between ‘link’ and ‘link text’ stages now mostly lies in how I find the strings to search for (the former is pre-encoded, the later is done by searching body text), the actual searches are handled in a centralized and consistent manner.
Postscript
I have now implemented the above (I was startled at how easy it was, honestly) and I’m seeing exactly what I expect to see.
Given the test document below, where I add duplicates of the Alertness feat (in the same ‘source’ I refer to it) and the Skill Focus feat (in the same document but a ‘different source’ from the same publisher) and they are found appropriately.
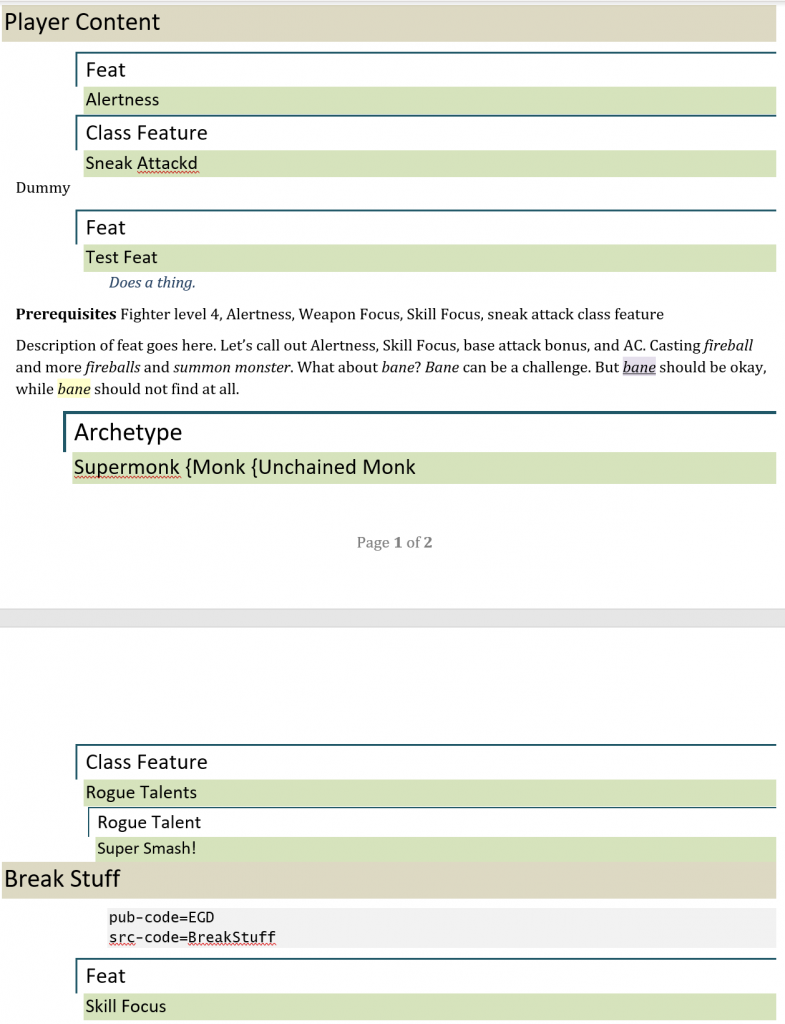
The markup is a little funky but it works well for me. You can’t see it, but everything up to ‘Break Stuff’ has a publisher of ‘EGD’ and a source of ‘Test’. ‘Break Stuff’ has publisher and source of ‘EGD’ and ‘BreakStuff’. I often put multiple sources in a single document to reduce processing and editing overhead.
When I parse and link the prereqs on ‘Test Feat’ I see exactly what I expect to:
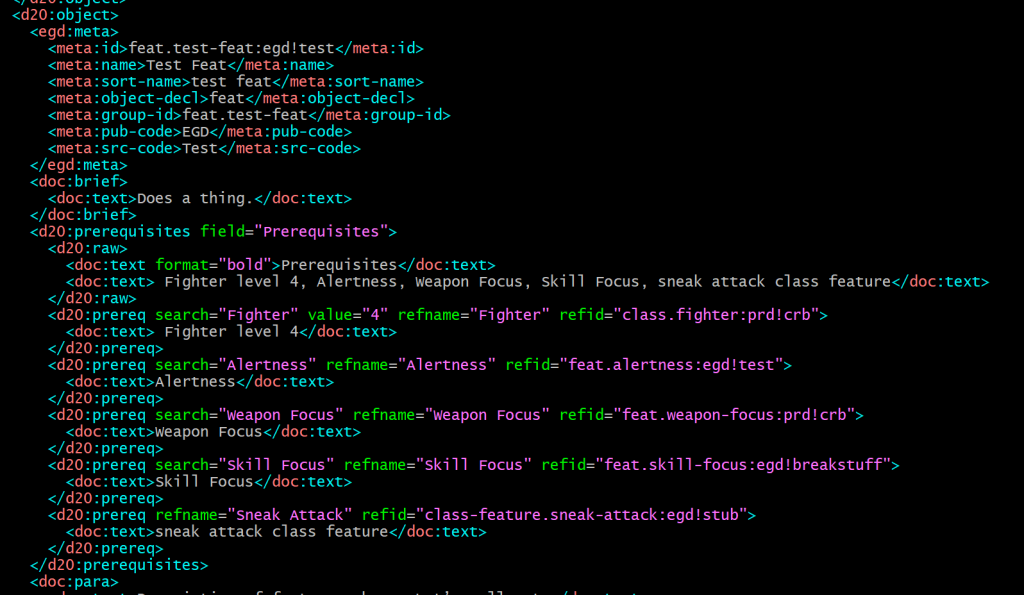
That is,
- ‘Fighter’ maps to ‘class-fighter:prd!crb’ (i.e. fighter from the Core Rulebook)
- ‘Alertness’ maps to ‘feat.alertness:egd!test’ (i.e. the one in this source)
- ‘Weapon Focus’ maps to ‘feat.weapon-focus:prd!crb’ (feat from the Core Rulebook)
- ‘Skill Focus’ maps to ‘feat.skill-focus:egd!breakstuff’ (feat from ‘Break Stuff’ — same publisher, different source)
- ‘sneak attack class feature’ maps to ‘class-feature.sneak-attack:egd!stub’ (stub object synthesized in the index file, because all the ‘actual’ sneak attack class features are in classes or archetypes)
If we look at the make output (which includes trace statements specifically for this reason… I usually turn them off), we can see that most of links are resolved pretty simply, but the Alertness and Skill Focus matches have to dig a little harder, using (pub, src) and (pub) filters to get the right ones. We also see that ‘summon monster magic’ doesn’t turn up a link at all (italicized text often indicates magic, but there is no spell or magic item called ‘summon monster’) and ‘bane magic’ doesn’t find a unique match (the spell and the weapon quality are both magic, but neither is the definitive object).
I am very happy with how this is turning out.