Uniquely identifying objects is one of the more vexing activities in building the Echelon Reference Series. It is good to have a human-readable ID (it’s a great kindness to the developer to be able to see that yes, a parsed link looks like it does refer to the correct item, ‘d4e3838ef2’ is not particularly helpful that way). Naturally, the first thing that comes to mind is a string joining the object type and the object name… or so one might think.
It turns out that fails horribly, because there are so many things of the same type with the same name. Almost all classes have a class feature called ‘weapon and armor proficiency’… I just counted 380 ‘class-feature.weapon-and-armor-proficiency’ objects in my data store. This one’s actually not so bad, as far as identifiers are concerned, because appending the ID of the parent object (class or archetype) makes all of these unique.
Of greater concern are cases where two objects have the same name either because they are intended to be the same object (most often when published in two sources from the same publisher) or are intended to be different objects (different publishers, or in at least one publisher’s case, different source documents with objects of the same name and type).
This leads to a potential solution: append the publisher and source to the ID. I do this today manually when resolving ID collisions, but why not do it automatically, for all objects?
Let’s see what this means to me.
Quick Wins
First, this gets me unique IDs for almost everything. The only time I don’t get a unique ID is when there are two objects of the same type in the same source document. Off the top of my head, the only place this happens all that much is with ‘buildings’ in Pathfinder RPG Ultimate Campaigns, where there are two things called ‘buildings’ that actually refer to differently-implemented game objects. I probably will end up simply creating two types of ‘building’ in my taxonomy and being specific about which one is being used.
Oh, and one archetype that named two features exactly the same, at different levels. I solved this one by merging the two features and saying what is gained at each of the two levels.
Things to Think About
This is a longer list, and contains complications in implementation. More importantly, though, they bring some powerful benefits.
This is likely to be more of an opportunity than an obstacle. If I have a potential link (italicized strings often indicate magic — spell or item — so I tend to check) it would be great if I can hook those up automatically. Today if I need to qualify the link with a differencing mark (i.e. two books have an aegis spell, so each gets a differencing mark appended) the name alone won’t match. That is, ‘aegis’ is not the same as ‘aegis:notnw’ or ‘aegis:dm’. I have two potential gains here, though.
First, when I find that I’ve got a potential reference that matches multiple objects, I can report this during parsing so I can remediate. If I ignore the publisher and source codes, ‘aegis’ matches two objects equally well, so raise a notice and move on. This does suggest that I should periodically review my semi-duplicates (the ones that match except for the publisher and source codes) and either accept (flag as “these names collide but I say they are different objects and I am okay with them colliding” or remediate (“these are actually the same thing, they republished from another of their books, replace one with a refcopy”) them. Way less work than I do now, manually remediating all of them. In fact, because the flags would themselves be metadata, I can probably set them at the document level, rather than individually.
Second, and better, most of the time an unqualified reference refers to an object published in the same source or by the same publisher. If I find aegis in Open Design’s Deep Magic I can be reasonably certain it’s referring to their aegis spell, and if I find it in Necromancers of the Northwest’s Advanced Arcana 7 I can be pretty sure it’s referring to that one. If I find it another source — Necromancers of the Northwest’s Necromancer’s Almanac 2016, say — I can still be pretty confident it prefers to the Advanced Arcana 7 version since it’s still the same publisher. This would fail if Necromancers of the Northwest had two spells called ‘aegis’ in other sources, but that is easily fixed by affixing the source code. That is, if there were two aegis spells, one in Advanced Arcana 7 and one in Advanced Arcana 8, when I’m in Necromancer’s Almanac 2016 I can append ‘::aa7’ to the spell name and it will use that and the inherited ‘notnw’ publisher code to determine the correct aegis spell.
I’ll have to implement this a little differently, though. Overloading the search strings is going to be really troublesome, especially since I need to be able to ignore them. I think the correct path is:
- Implement the search strings as I have them today, without the differencing marks (publisher and source codes).
- In the search string element, identify the game objects that match (fully-qualified IDs, yay!), the weight and offset, and the publisher and source codes.
- On matching the search string, look for the best matched object (greatest weight, lowest offset), taking into account the publisher and source codes. Publisher and source codes should probably be a tie-breaker rather than a major determinant.
Let’s see what that might look like.
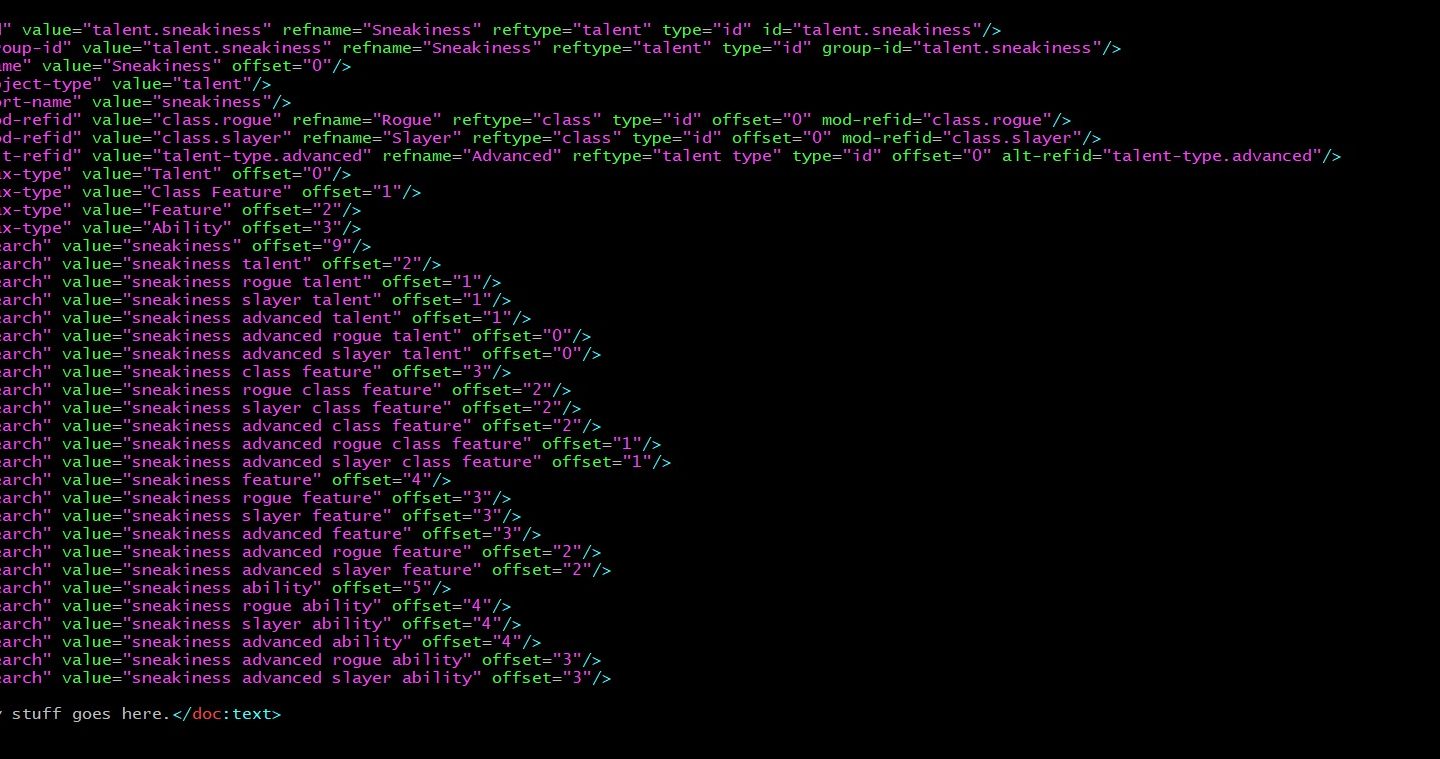
- ‘Improved evasion advanced rogue talent’: unique match, one object. Regardless of whether I’m in the same source document, a different document from the same publisher, or a different document from a different publisher, it won’t matter.
- ‘Sneak attack class feature’ will have many hits, it’s a fairly common class feature. In the Core Rulebook it’s actually not unique. The rogue and the arcane trickster both have this talent. No resolution, even with publisher and source codes.
- ‘Sneak attack rogue class feature’ is unique, and maps to class-feature.sneak-attack/class.rogue.pzo.crb.
- ‘Lay on hands paladin class feature’ is unique.
- ‘Lay on hands class feature’ actually shows up in three places: the PRD CRB, a Paizo splatbook, and a Rite Publishing archetype. On its own, it is not sufficient to uniquely identify an object. However:
- In the CRB, I will assume it means the paladin class feature: highest weight, lowest offset (1 — it’s in a class), and publisher and source match.
- In the source with the scar seeker, I will assume it means the scar seeker class feature: highest weight, lowest offset, and publisher and source match.
- Any other Paizo source, I cannot decide: two objects with the same weight and offset, publisher matches but sources don’t. Must qualify to decide.
- Any Rite Publishing source, I will assume it means the merciful inquisitor archetype. Highest weight, lowest offset, and publisher and source match.
- Any other source, I cannot decide: all three objects have the same weight and offset. Must qualify to decide.
- IN ANY CASE, if I create a naked ‘lay on hands class feature’ (i.e. object of class feature type, with no parent object), THIS ALWAYS WINS. Best weight, offset 0: exact match always wins.
- ‘Aegis spell’ shows up twice… but there also is an ‘aegis mythic spell’ in Legendary Games’ Mythic Spell Compendium.
- ‘Aegis mythic spell’ will never win here. It has the same weight as the two ‘aegis spell’ objects, but a higher offset and thus gets excluded. However, it does have a reference to ‘aegis spell’ that will need to be resolved.
- In any Necromancers of the Northwest source, their copy wins.
- In any Open Design source, their copy wins.
- Anywhere else, no winner without qualification.
Are there ways to improve this? I can see some.
- The above assumes all Paizo sources, including the PRD, are encoded with the same publisher code. If I keep the PRD sources distinct, then within the PRD they should resolve with a preference toward the PRD. This probably doesn’t work well for me, because this means that within the PZO files there is no implicit connection to the PRD.
- Legendary Games’ Mythic Spell Compendium gives a lot of support to Open Design’s Deep Magic. It could be convenient for it to favor Deep Magic spells when resolving links.
These can both be satisfied by having a ‘secondary’ or ‘preferred alternate’ indicator. I use colons for the delimiter on publisher and source codes, I could use semicolons for the secondary ones. If I give them a fraction of the weight of the other codes that should solve it. That is, my Core Rulebook source document has pubcode=prd and sourcecode=crb, all my ‘PZO’ file set has ‘pubcode=pzo’ and ‘altpubcode=prd’. The pubcode and source code get applied to objects in the source documents, the altcodes apply only when resolving links within that source document. This allows me, in Mythic Spell Compendium, to have altpubcode=’opendesign’ and altsourcecode=’dm’, and when I find a reference to ‘aegis spell’ I will default to the Deep Magic version.
Oh my me. Another thing this gives me… those little ‘UC’ and ‘UM’ marks we find in books all the time, showing where a particular referenced item is defined? This lets me do that for all links if I so choose. And I can build a killer concordance in the book that maps these back to the source documents… assuming I don’t run into Product Identity issues. (And I’ve got a built-in string substitution mechanism that lets me override publisher names and document titles very easily, and I can pretty easily add another facility that lets me put alias descriptions on the documents, as Legendary Games does with things like ‘BA = Guide for playing characters whose bloodine is angelic’
Closing Comments
A bit rambly again, but I think I’ve clarified my thoughts. For myself, at least.
Implementational Changes
The following:
- Add ‘headings’ to normalization parameters, so I can inherit values from the document in addition to the game entities. Specifically needed so I can use the new codes described below.
- Add support for ‘pub-code’ and ‘source-code’. Assign primarily to headings, but may be overridden and assigned to objects either directly or via declaration (though the latter is a bit nonsensical, in that it defines the object as coming from another document).
- Add support for ‘pub-alt’ and ‘source-alt’. Assign primarily to headings, but may be overridden and assigned to objects either directly or via declaration (but not from heading — the only reason to assign to the object is when overriding the document alts).
- Support multiple alts? Worth thinking about, probably easier to implement than no more than one.
- Include pub-code and source-code fields in parsing links (regex might be something like /^([^:]+?)(:[^:]+)?(::[^:]+)?$/, for name followed by optional pub-code followed by optional source-code).
- Link parsing currently works on name only (basically), with some contextual considerations. Expand to include other text in the search string. That is, right now if I find ‘Knowledge domain’ in plain text it will pick up as (Knowledge skill) ‘domain’ automatically (I search for feat and skill names). I can indicate type by encoding (change ‘Knowledge’ to ‘Knowledge{domain}’ and apply the Ref style), but expand reference parsing so I can simply highlight ‘Knowledge domain’ and it will resolve that search string, returning a string that is a link the Knowledge domain and plaintext ‘domain’.
- I had some concern about setting the publisher and source codes explicitly, and how to match them on the automated searches. On reconsideration it’s a non-issue: if I feel the need to append the codes explicitly I’ll be right there and can highlight the entire thing and apply the Ref style. Solved!
- When parsing links, apply pub-alt and source-alt if present, at a lower weight than the codes.
Eh… should be done tomorrow.