Any time you build a nontrivial data model, you have to expect the original assumptions will be tested, and found wanting.
You’re not going to get it right the first time.
In fact, I’ve read design books — data modeling and software design — that advise the reader to be prepared to throw the first few attempts out, as you learn more about the data. (No, ‘Agile’ doesn’t prevent this, but it usually makes the throwaways a little smaller.)
The false assumption this time has to do with cardinality between objects. To be fair, often gets mistaken in data models.
I was able to kludge around subdomains with more than one associated domain, and talents that can be taken more than one way (such as a “rogue talent” that can also be taken by slayers and investigators). Archetypes that modify multiple classes kind of broke things for me. I couldn’t model that well.
Time for a change.
Attribute to Element
The back end of my data store is implemented entirely in XML. I favor attributes for tightly-related information that has a single value per entity (such as an ID — an object should have only one ID, so it’s a great candidate for an attribute). The name also can be a good attribute, as can the object type, and… uh oh.
An object doesn’t have to have one name. An object might have a primary or canonical name, but there are several others possible.
- Abbreviation (Strength ability score is often referred to as ‘Str’).
- Alias (‘aka’ in my model, an alternate name for the object).
- Plural (what you call more than one of of the object).
Any one of these could be used in a search, and I will want to be able to search on them. I used to treat each kind of name as a special case, but I realized I can make them all ‘names’ and just give them different weights, in case both exist. That is, searching for ‘wishes’ should find the ‘wish’ spell, unless there is something actually called ‘wishes’: the plural has lower weight than the canonical name.
More importantly, and the reason I started this, I used to have ‘mod-refid’ and an ‘alt-refid’ attributes. In an archetype, the mod-refid contains the reference ID of the class the archetype modifies, and in a racial archetype the alt-refid could contain the reference ID of the archetype’s race (at first I was going to call it the ‘associated refid’, but I knew I couldn’t use ‘ass-refid’ as the attribute name because I am still 14 years old inside). Just like I can now have multiple names, I can have multiple ‘modified objects’. I need to be able to have more than one value.
So, child elements it shall be. These child elements will themselves have multiple attributes (the refid value, and the name and type of the referenced object). It used to be sufficient to have these additional values as attributes, but because they are specific to the referenced object and I can have more than one of them, they belong to the metadata element.
Happily, it was not necessary to change how I mark up the source texts (good, there are hundreds of files involved!). The big difference is that I can now have multiple values encoded: “this archetype modifies the monk class” (with notes in the archetype text saying “and also unchained monk”) can now be encoded as “this archetype modifies the monk and unchained monk classes”.
Creating Object IDs
Ideally, each object will have a unique ID. To try to do this I used to construct the ID by concatenating the multiple elements that defined the object. That is, the combination of (object type, object name), (parent type, parent name), (modifies type, modifies name), (alternate type, alternate name), with different delimiters between them.
This was fine when each object could have no more than one modifies/alternate/parent kind of relationship. Now that I can allow more than one, that’s not going to work.. and it turns out that for indexing and searching, it’s not even needed. I assign a surrogate key to each object, so I’ve got something to connect the search strings to, and a generic ID I can use when I need to hook up to a group rather than a specific instance (‘class-feature.sneak-attack’ is sufficient for the sneak attack class feature, since I know what the class feature is called and what it is, but not which class it’s from… I can’t reasonably qualify it further, so I don’t try). I will certainly want to have a more precise ID for the objects when I go to render them, so I can link directly to the specific items in my PDFs, but I can create those at the time, using increased contextual information of where it’s being used.
That is, if I’m presenting the Demon subdomain on its own (no connections needed) I can use ‘subdomain.demon’ as the object ID in my PDF, and the fury of the abyss replacement power will be ‘granted-power.fury-of-the-abyss/subdomain.demon’. If I’m presenting the Demon subdomain specifically as relating to the Chaos domain, I use that context to give it the ID ‘subdomain.demon=domain.chaos’ and fury of the abyss gets ‘granted-power.fury-of-the-abyss/subdomain.demon=domain.chaos’ (long-winded, certainly, but readable… consider it a courtesy to the developer). Then I can have hyperlinks take me directly to each object as needed.
On Duplicate IDs
I just ran a query against my entire data set, looking for duplicate IDs. In my full data set I have 83,589 objects (today, at least; that number will go up). Of these, 82,015 IDs are unique, on just (object type, object name) [with (parent type, parent_name) for child objects). Of the remaining 1,574, I see many that are actual duplicates (same spell presented in two source books, such as a Paizo Player Companion and a hardcover; these should get merged, or differenced if there are substantive differences between them), name conflict (two archetypes from different publishers; these will get the names differenced), or a child object of one of the above (monster is presented twice, both have the same special abilities, so the IDs of the monsters and of the special abilities will be the same).
This is quite good news. These are easy to fix, and it means I can use much simpler IDs than I did originally.
Searching and Indexing
Changing how the data is represented clearly changes how the data is used. Funnily enough, the implementation actually got simpler.
Building Search Keys
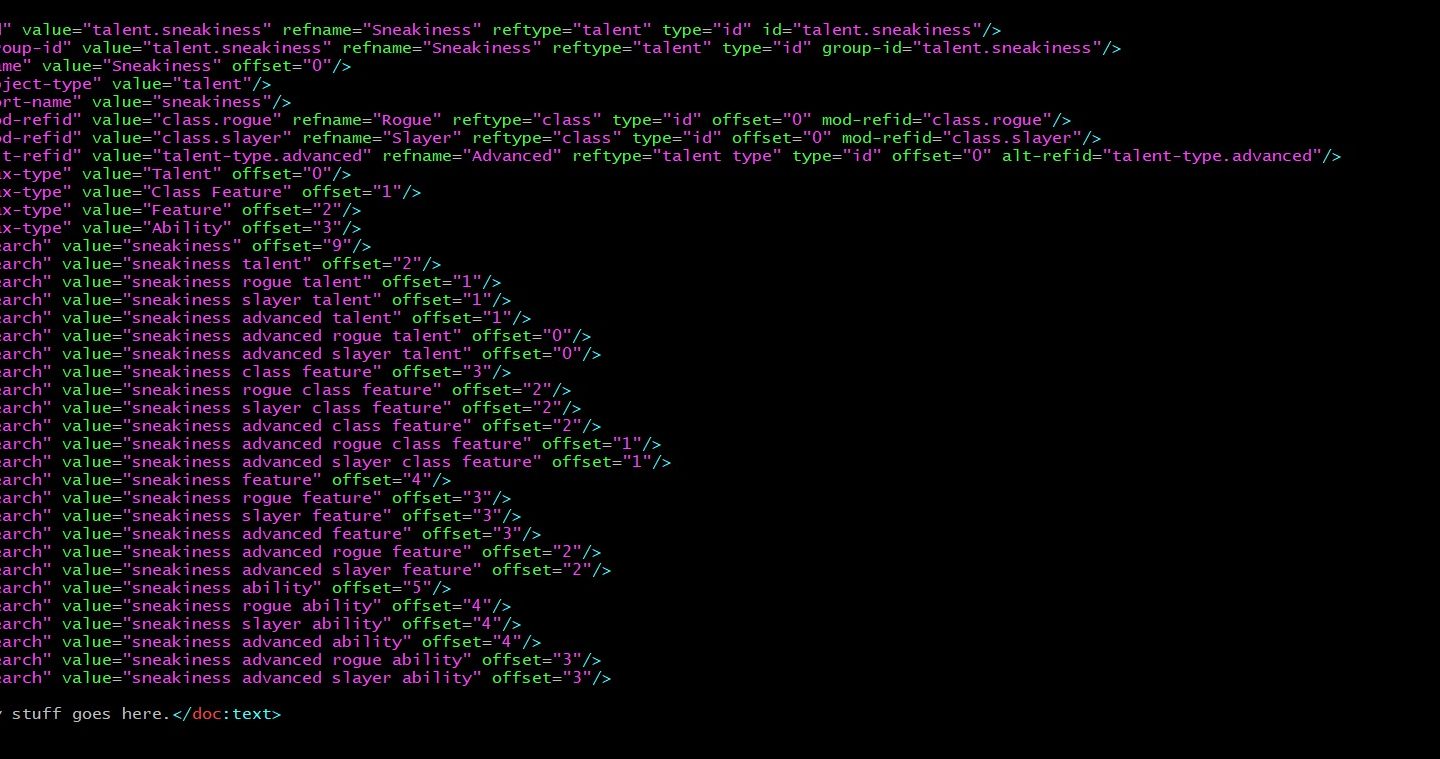
When parsing each object, I examine the metadata and build a set of search keys based on combinations of fields. Specifically, for each tuple of (name, alt-refid, mod-refid, and tax-type) [last value is the ‘taxonomy type’, a hierarchical categorization of game objects], I generate the following metadata objects:
- <egd:meta type=”search” value=”(name, alt-refname, mod-refname, tax-name)” offset=”#” weight=”#” />
- <egd:meta type=”qual-type” value=”(alt-refname, mod-refname, tax-name)” offset=”#” weight=”#” />
Also, if the game object is the child of another (such as a class feature or a bloodline power), the following search entries will be present:
- <egd:meta type=”search” value=”(name, parent-refname, tax-name)” offset=”#” weight=”#” />
That is, I make a string concatenating the name, name of the alternate-reference object, name of the modified-referenced object, and the taxonomy entry (or the name, parent name, and taxonomy entry name). The weight is calculated by how much the search term matches the object, and the offset is how far this is from a perfect match. “Evasion class feature’ will have a weight of 4 (ability -> feature -> class feature, +name) whether it is referring to an actual class feature (rogue) or the master ninja trick (because a master ninja trick is a ninja trick is a class feature). The offset of the rogue ability will be 1 (exact match would be ‘evasion rogue class feature’, this is one step away), the offset of the master ninja trick would be 2 (exact match would be ‘evasion master ninja trick’, and ‘master ninja trick’ is two steps away from ‘class feature’).
Aliases, plurals, and abbreviations all have ‘fractional weight/offset’ (0.9/0.1 when I explicitly set them, 0.8/0.2 when they are calculated). If I find ‘bonus feats fighter class feature’ I want it to have more weight than ‘bonus feat class feature’: the name isn’t an exact match but the other elements have greater thunk than the exact-match name — many classes have a ‘bonus feat’ feature, but only the fighter has the fighter class feature). (Okay, yes, arguably fighter archetypes sort of do as well, but that’s another matter for another blog post.)
Building the Index
The old index code would group everything by ID, then when searching I would look for the elements with the best-matching values (lowest offset). This worked pretty well overall, but the changes I’m making here will let it work better.
First, I identify all the unique search strings (120,450 in my current ‘PRD-Only’ data set, 422,200 in the full set… so far). For each search string I find all objects that have that search string, then identify the objects with the highest weight and then lowest offset. If there is only one, I have my best match and I assign the ID of that object to the search string. If I have more than one but they all have the same group ID (i.e. same taxonomy type and name), I assign the group ID. For instance, ‘evasion class feature’ has its best match as the evasion class feature, but there are multiple classes with that class feature. I can’t pick one of them because they have the same weight and offset, but I do still know that it’s a ‘class feature called evasion’, and that is a thing that exists… I just don’t know which one is being referred to specifically, but it’s probably being referred to generally anyway.
So, I build an index of all the search strings, and attach each to the best-matching object or group of objects. This will resolve links much faster than I had before, because it’s now a quick search of a single array — a big array, but still a sorted array rather than a hierarchical data scan — and then reading the predetermined best-match instead of trying to figure it out at the time. I pay a small amount of time and effort up front for big gains downstream.
Building Search Strings
In addition to trying to match identified strings to objects, I do certain searches (feats and skills, scores) on other text. I build (rather large) regular expressions of all the object names, then examine each piece of text to see if there are eligible substrings that match. To do this I need the full set of object names and types, so those go into the index file as well. I recently realized that instead of calculating these regular expressions at parse time, I can calculate them at index time and simply load them later. That should reduce my parsing time also.
Some Stats
Part of making a change like this is evaluating the results. In this case I say a search string is ‘good’ if it identifies a unique item, ‘okay’ if it identifies a group, and ‘poor’ if I can’t find a good match at all. A ‘good’ string might in fact match several items, but one of them will be ‘best’, enough that I will assume that unless the search is further qualified, it is correct.
| Search String Grade | PRD-Only | % | PRD+PZO | % | 3pp+PRD | % | All | % |
|---|---|---|---|---|---|---|---|---|
| Good Search String | 114,577 | 95.12 | 216,206 | 94.88 | 299,916 | 94.21 | 397,246 | 94.08 |
| Okay Search String | 2,354 | 1.95 | 6,028 | 2.64 | 6,736 | 2.11 | 10,479 | 2.48 |
| Poor Search String | 3,519 | 2.92 | 5,627 | 2.46 | 11,683 | 3.67 | 14,475 | 3.42 |
| Total | 120,450 | 100.00 | 227,861 | 100.00 | 318,335 | 100.00 | 422,200 | 100.00 |
I’ll be honest, I’m a bit stunned that very close to 95% of all search string are ‘good’, especially considering how many of those strings are name only, with no qualifiers. Even where I don’t get a unique match, I have almost 2.5% that are ‘okay’, meaning it uniquely identifies a unique (name, type) tuple but not a single item. These will mostly be ‘child elements’ such as class features or bloodline powers, and typically we don’t even want those to be unique (I don’t care which class you got evasion from, you have the evasion class feature).
This is very encouraging. It means I can expect to have almost all my references resolve quite well, and it identifies a relatively small number of objects I’ll want to look more closely at. In some cases I’ll need to difference the names (two spells with the same name — right now they’ll have the same search string despite being totally separate objects) or will want to add ‘common objects’ (evasion class feature that defines the evasion rules and acts as an anchor to references to ‘evasion class feature’ (exact match so links resolve… and I can put it into a ‘universal features’ list), or do something else, will vary. In any case I’m getting quite close to being able to uniquely identify, in text, each object in the data store, despite simplifying the ID creation.
Closing Comments
I put these changes off for a long time because I expected them to be challenging. It turns out that while there is work involved, they mostly simplify my code. More powerful and simpler to implement? Sign me up!
This is fascinating work. I have actually been designing a streamlined RPG rule set to use on a completely new project, and found the crossover between class abilities make that part of the job so much easier. I created an ability called one with nature that combines ranger, Hunter, and Druid nature abilities, an ability called studied eye, that combines investigator and rogue abilities, combined panache, inspiration, grit, ski points, magus pool and others into a single resource pool ability and so on. I haven’t read all of this but would love to over time.
Ah yes, a man after my own heart. I’ve had similar thoughts regarding these topics in the past.
One of the first steps, I think, is coming up with standard definitions for things, then building up from there. For instance, I see a difference between ‘score’ and ‘pool’ (measure of something, and fairly static, vs. an expendable resource that fluctuates through use), and between ‘ability’ and ‘feature’ (thing you can do vs. how you get it: ‘evasion ability’ lets you take no damage on certain successful saves, ‘evasion class feature’ gives you the evasion ability).
After that, we get into how the abilities are grouped and granted. A big, big part of why I started the Echelon Reference Series was trying to get a big picture view of the various topics. I can see overhauling the talent system, and making (for example) ‘talents’ a common pool of abilities, and various ‘talent lists’ granting them as needed. Or rather, I can see making talent lists ‘purpose driven’ rather than class-oriented. Just like a vigilante gets ‘vigilante talents’ and ‘social talents’, I imagine it could be possible to group talents into more cohesive sets, then granting those sets. Think ‘weapon groups, but for talents’. :)