Let’s get everything under one roof here, or at least, on one page. Here are my collected notes on Seventh Sanctum files, which are available for download from Seventh Sanctum. These notes collate and summarize the posts below.
- Imagination Helper: Seventh Sanctum, introducing the topic.
- Seventh Sanctum: Data Files, describing the three file types at a high level. I compared the format to that used by my own random table roller.
- Seventh Sanctum: Configuration Files, describing the syntax and probable use of these files.
- Seventh Sanctum: Vocabulary Files, describing simple string generation files. For a value of ‘simple’, there are some subtleties here I didn’t anticipate.
- Seventh Sanctum: Seed Files, describing the most daunting format with the most complex processing. Dynamically altering or replacing tables, during resolution… cool, but trippy.
- Seventh Sanctum: Proof I Understand, outlining how I plan to test my understanding of the files.
- Seventh Sanctum: Nailed It, showing the results of my tests. Looks like I did in fact understand the files.
I have not spoken with Steven Savage, the creator of Seventh Sanctum. I am wholly confident I am not using his terms for the concepts below. Ah well, they work for me.
I’ve received email from Steven Savage, the creator of Seventh Sanctum. I was correct: my vocabulary doesn’t match his, but I’ve fundamentally described everything correctly.
File Formats
Seventh Sanctum files come in three flavors. I call them ‘configuration’, ‘vocabulary’, and ‘seed’.
In the actual files, indentation is done with tab characters. I’ll use two spaces at the start of a line to mean a single tab character.
In all files, double-slashes (‘//’) mark the start of a comment, and everything after that is ignored. I think I’ve only seen comment markers at the start of the line (sometimes after white space). I don’t remember seeing a comment after content.
Configuration Files
These files map labels to table names to the content used for random generation. That is, each file is a series of title, table name, and list of import tables.
From pizzaconfdat.txt:
Any
ANY
pizzamixdat.txt
pizzameatdat.txt
pizzavegdate.txt
pizzadat.txt
Combinations
COMBO
pizzamixdat.txt
pizzadat.txt
Meat Pizzas
MEAT
pizzameatdat.txt
pizzadat.txt
Vegetable Pizzas
VEG
pizzavegdat.txt
pizzadat.txtVery straightforward. When I decide to create a ‘Meat Pizzas’, the software will look under that heading and read pizzameatdat.txt and pizzadat.txt, then apply the contents of those files.
In this example, the imported files are vocabulary files (described below). This also can be used with seed files (described below). From mlponyconfdat.txt:
Either Gender
SEEDANY
mlponydat.txt
Male
SEEDMALE
mlponydat.txt
Female
SEEDFEMALE
mlponydat.txtNote that all three titles load the same seed file, mlponydat.txt, but have different seed names. This mapping file shows what entry point to use into the contents of mlponydat.txt.
I see no reason why a configuration file couldn’t import multiple seed files under a symbol. I don’t think I’ve seen it in practice, though. It does not seem appropriate to mix vocabulary and seed files in the import list.
Vocabulary Files
Vocabulary files contain a list of words and templates for choosing and outputting strings. There is some metadata on the words to guide word selection. From eranamegendat.txt:
//Vocab types:
//1 - Descriptor, Abstract
//2 - Desctiptor, Object
//4 - Descriptor, Being
//8 - Object
//16 - Object, Plural
//32 - Being
//64 - Abstract
//128 - Era
--CATEGORY
Generic
GENERIC
Biotechnology
BIOTECH
Exploration
EXPLORATION
Dark
DARK
--ORGANIZATION
4,128
The , ,
4,128,64
The , , of ,
--VOCABULARY
Accursed,39:depraved,evil,unholy
Advancing,7:exploration,growth
Adventerous,4:exploration
Adventure,72:exploration
Adventures,80:exploration
Adventuring,64:exploration
Afflicted,37:decay
Affliction,72:decay
Ailment,8:decay
Ailments,80:decay
// Eras
Aeon,128:extra
Age,128:extra
Century,128:extra
Cycle,128:extra
Epoch,128:extra
Era,128:extra
Time,128:extraThe first part of most vocabulary files is a map of types. This is a comment block (ignored by the engine) showing a table mapping numbers to type labels. All numbers I’ve seen here have been powers of 2: 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048. They will be used as bitmasks later, so words can have more than type, and choices can draw from multiple types of words.
The next section shown above is ‘CATEGORY’. I understand from a comment in one of the source files that this is to prevent overusing words from the same group. That is, to head off the ‘Angelic Era of Angels’. This section is entirely optional, and I think most files do not contain categories.
The third section shown above is ‘ORGANIZATION’. These are templates showing what word lists to draw on, and how to format the results. Each template is two rows. The first row is a comma-separated list of ‘word-numbers’, the second is a picture of the output. When picking a word, the engine scans the list of words, finding all whose type ‘and’ word-number is not 0. One of these words is then chosen and added to the output list. When applying to the picture, each comma (‘,’) marks where to put a word. If you want an actual comma, include ‘<COMMA>’ in the picture.
The last section is ‘VOCABULARY’. The simple form, used in files without categories, has just ‘word,type’. In files with categories, the format is ‘word,type:list,of,categories’.
Accursed,39:depraved,evil,unholy
Advancing,7:exploration,growth
Adventerous,4:exploration
Adventure,72:exploration
Adventures,80:explorationHere, I see
- ‘Accursed’ (word), types = 39 (32 | 4 | 2 | 1 — being, descriptor-being, descriptor-object, descriptor-abstract), categories ‘depraved’, ‘evil’, and ‘unholy’.
- ‘Advancing’ (word), types = 7 (4 | 2 | 1 — being, descriptor-being, descriptor-object, descriptor-abstract), categories ‘exploration’ and ‘growth’.
- Adventerous [sic] (word), types = 4 (descriptor-being), category ‘exploration’.
- Adventure (word), types = 72 (64 | 8 — abstract, object), categories ‘exploration’.
- Adventures (word), types = 80 (64 | 16 — abstract, object-plural)
If this file didn’t have categories, the vocabulary lines would look like this.
Accursed,39
Advancing,7
Adventerous,4
Adventure,72
Adventures,80Same types, no categories.
When resolving templates (from the ORGANIZATION section) below, we need words from the 4, 64, and 128 lists.
4,128
The , ,
4,128,64
The , , of ,
From the deeply abridged list above, ‘4’ is satisfied by ‘Accursed’, ‘Advancing’, and ‘Adventerous’ strings. 64 is satisfied only by ‘Adventures’. 128 isn’t satisfied by anything in this immediate list (but you can see some in the ‘file sample’ above).
When creating a template, it is not necessary to use only a single value. As with the word types, multiple values can be added (bitwise-or, actually) to make a value. For instance, if I want a descriptor, without caring about what type, I can use 7 as my search value. This will pick up all strings that are one or more of descriptor-abstract, descriptor-object, or descriptor-being.
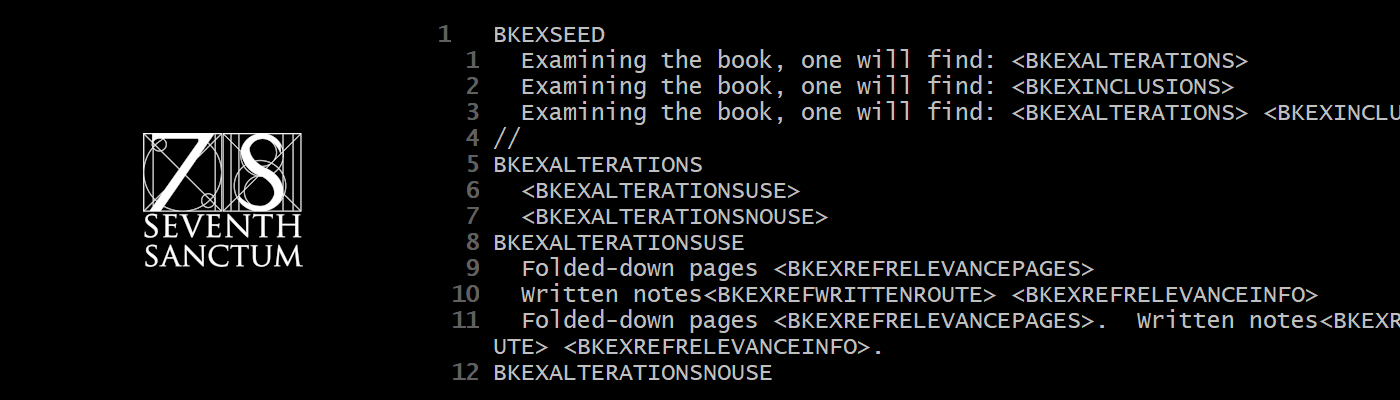
Seed Files
Seed files contain table definitions. Each table has a name (convention seems to be all caps + digits, no symbols) and rows/entries. Some entries look like ‘<*>’ and contain instructions to replace or append content of other tables. Heavily abridged (the entire file is 1,836 lines), maschooldat.txt has
//Seeds
SEED
The <ROUTEGETASSOCFRONT> <*GETSCHOOL><GENSCHOOLTYPE>.
The <*GETSCHOOL><GENSCHOOLTYPE> of <ROUTEGETASSOCBACK>.
The <*GETSCHOOL><GETSCHOOLDESC> <GENSCHOOLTYPE> of <ROUTEGETASSOCBACK>.
SEEDKNOWNRANGE
<REFSCHOOLREF> is <GENKNOWN> and <GENSPREAD>.
SEEDFOCUSES
<REFSCHOOLREF> has <REFREPCLASS> for <GENSCHOOLFOCUS>, and <REFFOCUSCLASS> <GENSCHOOLSKILLS>.
SEEDMOVES
<REFSCHOOLREF> is known for the "<SEEDINDVMOVES>".
<REFSCHOOLREF> is known for the <REFMOVEREP> "<SEEDINDVMOVES>".
<REFSCHOOLREF> is known for the "<SEEDINDVMOVES>" and the "<SEEDINDVMOVES>".
<REFSCHOOLREF> <REFMOVEGUARD> guards its ultimate technique, the "<SEEDINDVMOVES>".
SEEDINDVMOVES
<GETDESA> <GETACTB>
<GETDESA> <GETACTC>
<GETOBJA> <GETACTB>
GETSCHOOL
<*>
GENSCHOOLTYPE,true
Academy
GENKNOWN,true
<REFREPMEDWELL>
GENSPREAD,true
<REFSPREADLOCAL>
GENSCHOOLFOCUS,false
bureaucracy
discipline
decadance
literacy
scholarship
GENSCHOOLSKILLS,false
discipline
language skills
scholarship
training well-rounded individuals
<*>
GENSCHOOLTYPE,true
School
GENKNOWN,true
<REFREPFULL>
GENSPREAD,true
<REFSPREADMED>
GENSCHOOLFOCUS,false
discipline
intellectualism
loyalty
scholarship
GENSCHOOLSKILLS,false
discipline
training well-rounded individuals
tutoring skills
scholarship
<*>
GENSCHOOLTYPE,true
Path
GENKNOWN,true
<REFREPFULL>
GENSPREAD,true
<REFSPREADFULL>
GENSCHOOLFOCUS,false
commitment
discipline
independence
philosophy
mysticism(I shortened some of the lines to minimize word wrap.) Despite the simplicity of the format, this will take some unpacking.
- The first line is a comment. Simple, these get ignored.
- Second line, and any line with a table name (capital letters and digits) and no indent, are tables.
- Third through fifth lines, and all lines with exactly one tab character at the start, are rows/entries.
- When a table is resolved, one row/entry is selected and resolved.
- If the row/entry does not start with <*>, the row is processed and output.
- If the row/entry starts with <*>, it indicates a table modification. The child elements of this element are described below.
- All lines starting with exactly two tabs, identify a table to be modified.
- In GETSCHOOL, the lines with GENSCHOOLTYPE, GENKNOWN, and GENSPREAD have ‘,true’ at the end. These elements contain instructions to replace (or create) tables with those names. GENSCHOOLTYPE assigns a single row. I took this on first reading to be ‘setting a variable’, but that’s not exactly how it works. Even if that is basically the effect.
- In GETSCHOOL, the lines with GENSCHOOLFOCUS and GENSCHOOLSKILL have ‘,false’ at the end. These elements contain instructions to append to (or create) tables with those names.
- In this example, the ‘replace’ instructions have a single entry and the ‘append’ have multiple entries. I see no reason this is a rule. I expect you can replace a table with one having multiple entries, or append a single entry to a table.
- All lines starting with exactly three tabs are rows/entries to be added to the target table of a modification.
Now that the record syntax is out of the way, let’s look at how to read rows/entries.
I’ve been referring to them as ‘rows/entries’ because if the top-level objects are tables, their children would be rows. The ability to have instructions modifying tables in place of outputting rows leads me to want to call those ‘entries’.
The simplest entries are static strings, with no embedded tokens. The first GENSCHOOLFOCUS,false above has rows of ‘bureaucracy’, ‘discipline’, ‘decadence’ [sic], ‘literacy’, and ‘scholarship’. Here, they are added to a table called ‘GENSCHOOLFOCUS’. When that table is called, the string found is output.
A row can have tokens that indicate calls to other tables. The very first such row in the example above is
The <ROUTEGETASSOCFRONT> <*GETSCHOOL><GENSCHOOLTYPE>.- The <ROUTEGETASSOCFRONT> token calls the ROUTEGETASSOCFRONT table, and the output is inserted in place of the token.
- The <GENSCHOOLTYPE> token similarly calls the GENSCHOOLTYPE table, and the output is inserted in place of the token.
- The <*GETSCHOOL> token is different. It does call the GETSCHOOL table, but only the side-effects happen. There is no output inserted in place of the token. These calls are often used to manipulate other tables.
- By no small coincidence, GETSCHOOL has an instruction to modify GENSCHOOLTYPE, plus other table modifications.
The next simplest entries are ‘<*>’. “Process the child elements but output nothing”. Most often, ‘<*>’ marks child elements that are table modifications. ‘<*>’ is sometimes used for ‘null entries’ in a table. A table with three ‘<*>’ and ‘scholarship’ will output nothing 75% of the time and ‘scholarship’ 25% of the time.
I expect the combinations and concatenations of these things can get convoluted.
But the syntax is simple, at least.
Closing Comments
It’s fun figuring stuff out. It’s quicker when someone else already has. :)
I hope this is helpful.