
I have a very structured mind. I have been told that I am remarkably adept at organizing information and making sense of things.
I never been told I have a great imagination, and honestly, I don’t think I do. It’s a bit of an inconvenience when designing things — I can build almost anything, once I know what it is, but deciding what to build is a challenge.
My brain categorizes things and looks for patterns. A useful ability professionally, but when I want to design something, to be imaginative, it gets in the way because I keep falling back on familiar patterns. When I my campaigns fall in a rut they fall a long, long way, far enough to see stars in daytime.
That sucks, so I have developed a toolkit that hopefully helps me avoid that. I describe the five major components of it below.
Imagination Toolkit
In no particular order, since they can end up being used in just about any order, the major elements of my toolkit are
- Random Generation
- Structure and Template
- Challenge, Response, and Secret
- Crowd Sourcing
- Large RPG Library
Random Generation
First, random generation. Generate something randomly, then find a way to make it work. I usually generate a fairly large number of things randomly and look for something that sparks ideas. I have said before that the Tome of Adventure Design is my ‘weapon of mass construction’ (though I see it is still on my ‘review this’ list). Matt Finch did a great job building a large set of tables that can handle many situations and topics. Long ago I built a program that makes it easy for me to randomly generate strings from tables, and I’ve imported many of Matt’s tables into it. Then I combined them in strange ways, making combinations that are larger than suggested by the original tables (and mixing them up at the same time). When I devised Rime Tower I started with a randomly-generated list of place names — ‘Frozen Demense of Ice’ prompted me to think of ‘Rime Tower’ as a central feature, and things built from there. The Polyhedral Pantheon techniques start with this, assigning domains more or less randomly to deities in a way that sees consistent coverage (each domain or its subdomains are accessible to 4-6 gods, and each god has access to 4-6 domains) that results in some coherency in the randomness. Some randomness is pretty manual (Polyhedral Pantheons is a good example here), but a lot of it is handled for me by programs I write. The ‘Random Adventure Structure’ shown at the bottom of this post was generated by a script I hacked at lunch today.
Structure and Template
Second, I rely on structure and templates. By building to and around a framework I am prompted to be consistent in what I consider. The Entity Template I updated and posted a few days ago is a prime example of this. By always thinking of the relationships between things, how they can be recognized (whether present or not) and so on I am forced to look beyond the obvious of what I am dealing with. The relationships section forces me to think about how each entity fits in with other entities, and why people want the entity, or fear the entity, or have some other relationship to it. Rime Tower and the Ghost Hills were both further developed and documented, guided by the Entity Template.
Challenge, Response, and Secret
Third, I make use of an article I read from Dariel Quiogue in Johnn Four’s Roleplaying Tips newsletter: Challenge And Response: Designing Cultures For Your Game World Using Toynbee’s Principles. I actually adapted it a bit to incorporate a tip from one of Ray Winninger’s Dungeonmastery columns in Dragon Magazine: every significant game entity should have at least one secret. The result was my Challenge, Response, and Secret article… which is coming up on eleven years old. It basically amounts to asking the “five Ws (plus How?, but especially Why?”) until I am satisfied. Every element of an entity — character, place, thing — can have this asked. Gidr Farnsehame bound a dragon into a sword: why did he do it? what happened when he did? how did he manage it? who cares about it? why do they care? how is Nakeshrontaraan planning to break free of the binding? What is the red dragon planning to do after that? Does anyone want to help? Why? Does anyone want to prevent? Why? Where does the treasure go that Beobachten takes as payment? I can do this for a long, long time. I don’t even need to find answers, the questions themselves might become secrets associated with the entity.
Crowd Sourcing
Fourth, I take advantage of crowd sourcing. If I can get others interested in the topic I can lean on their ideas — if not to use as they are presented, then to spark my own ideas. GreyKnight is a wonderful resource for this if you can get his attention — he saw the ‘Some More Randomness’ post I linked a couple paragraphs ago and Random Leads to Awesome happened. The recent Seekers of Lore Microscope and Lexicon exercise was a crowd sourcing exercise that was going quite well until everyone got too busy. This tool gets relatively little description here because it is a fairly new addition. Historically I have always been willing to accept and consider suggestions from others, only recently have I begun to solicit them.
Large RPG Library
Finally, I have an RPG library that quite possibly weighs half a ton… and that’s the PDF portion. (I kid! That’s the physical RPG books, we moved probably about 3,000 pounds of books last year when we moved house). Once I’ve got an idea and some direction chosen, I can look for relevant and related content in those books and find something to build on or from. I also have a large hard drive full of PDFs and an entire world wide web of blogs and other online sources of content to help me flesh things out.
Closing Comments
These all tie together into my Campaign and Scenario Design processes. The Node-Based Megadungeon was designed, to the degree of detail it was, using these processes. The sandbox I’m building right now (have to remember to build a Hall of Fame page for it, I think) is being developed using these processes.
Sample Random Adventure Structure
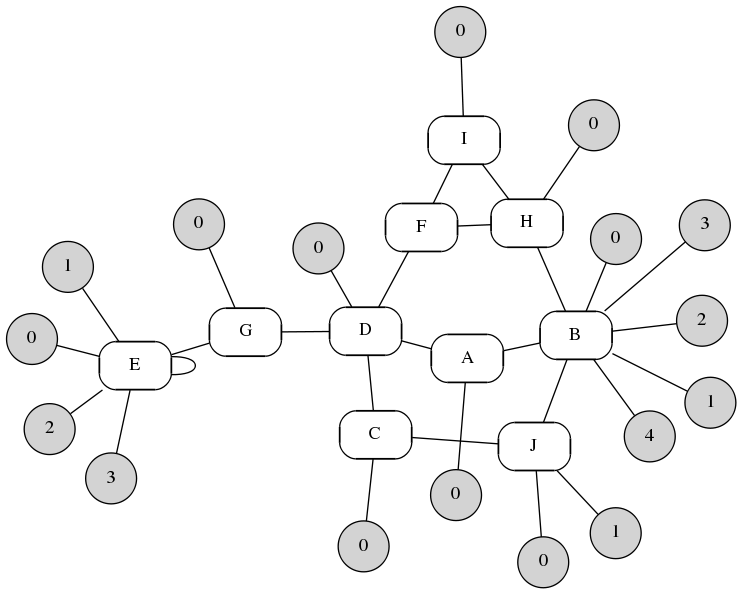
The diagram below might be used for an adventure structure. I identify the major elements of the adventure, but not the navigation paths through them. Certain conditions may need to apply in order to advance (“you need the blue key!” to go from H to I… or you might find the secret path from F to I) so it might be necessary to successfully ‘complete’ a number of the encounters, but the order they are done is largely uncontrolled. To generate this diagram I wrote a program that took the specified number of areas (ten), made sure each was connected to at least one (possibly itself) and may have a sub-element (the greyed and numbered circles), then I randomly joined them up a certain number of times (with some percentage of potential links actually being sub-elements).
Just looking at it I might consider I being the ‘boss room’. C or J might be the primary entrance. With each having a large number of sub-elements and being at opposite ends of the structure, B and E could be showpiece encounters of some sort. E probably isn’t critical to success since it’s at the end of a linear chain, but it’s possible B could be because of how well-connected it is. E is even self-referential, something about E ‘connects it to itself’. I don’t know yet what it means, but there could be something special about it — perhaps a ‘state change’ of some sort, as action or consequence elsewhere changes what E means. F doesn’t have a sub-element but does have a connection to the boss room, so I can imagine the connection is itself special, and probably either a secret way in, or a more difficult but advantageous way in.
I don’t know exactly what it all means yet, but it has me thinking. There are relationships implied by the diagram that I will want to enact somehow later in the design, and they will keep me thinking about how to satisfy them rather than on accepting the simple solutions.
I have a useful mental tool that I use to come up with interesting solutions (outside gaming too). I’m not 100% on putting it into words, but a decent version might be “Does it need to be that way?”.
First you need to find some basic assumptions: this can be harder than it seems because assumptions are usually beneath our notice. Make a simple statement and dig into it with a few levels of questions like “Why is that?” or “What exactly is an X?” After you define X as a type of Y, you can ask “What is a Y?”, and so on.
Hopefully at some point in this digging you will hit some statement which is so obvious that you can’t think how to dig any deeper. For example, in the “Jenda” entry on http://www.kjd-imc.org/blog/random-leads-to-awesome/ , the basic assumption is “Fantasy humans are just humans.”. So then you can ask “Does it need to be that way?”, and it turns out the answer is no! The fantasy humans could look and behave like regular humans, and might even think of themselves in those terms; but perhaps there is a strange secret about their actual origin.
Your algorithm at the end there (if I understand it correctly) can generate graphs made of two disjoint pieces.
The simplest way to avoid this is:
* start with one node
* for the desired number of nodes:
** pick an existing node, add a new edge coming from it to a new node
* now you have a single connected piece
* randomly add more edges until you reach the desired number
However, this results in the first nodes placed getting more than their fair share of edges.
You can avoid that with the following random-walk algorithm which is pretty cool:
* start with all N nodes, no edges
* pick a starting node, make it your current position, and mark that node
* while unmarked nodes exist:
** randomly select any node
** move to that node
** if it is unmarked, add an edge between this node and your previous one, then mark the node
* now you have a single connected piece
* randomly add more edges until you reach the desired number
I did cherry pick the graph used here. I had some that were disjoint, others that were a spiky mess. That second algorithm looks like it solves the first part well, but offhand I don’t see a way to ensure a planarity.
I’ll update the script later to ensure no disjoint graphs. I need to finish my breakfast and get to work.
Oh, I didn’t think about planarity, sorry. I’ll get back to you on that as I’m at work myself. :-)
Planarity is nice to have, but not an absolute requirement. I capture the intermediate form (file that goes into neato for layout) and I’m not such a purist that I’m above tweaking the links, so as long as it’s close I’m happy.
The simple-minded approach is just to do a planarity test after each putative modification, and reject new edges that would produce a nonplanar graph. Alternatively, just test the end result and throw the whole thing away. Planarity tests usually run in linear time so it’s not too onerous, but generate-and-discard has no upper bound on total runtime of course. Boyer-Myrvold’s testing algorithm might be worth a look: it can actually identify the nonplanar “knot” in your graph, so you might be able to use this to patch up the problem (see http://www.ogdf.net/doc-ogdf-dev/classogdf_1_1_extract_kuratowskis.html ).
A cleaner approach is to try and generate a planar graph to start with. Pick some random points, compute a Delaunay triangulation of them in O(n log n) time, then find a minimum spanning tree using the algorithm of your choice, most of which are also O(n log n). Prim’s or Kruskal’s algorithms would do the trick.
Now you have a minimal graph that connects all the nodes into a single connected piece, and you can add more edges if desired.
Note that the Delaunay triangulation is basically a maximal such graph, in that adding more edges to it (except round the edges) would result in a nonplanar graph. This might also be useful to you in some way.
I think I will have to think about how this works. I understood every word you used, and yet the comment as a whole needs more effort on my part…
Hmm. Delaunay triangulation looks interesting, but depends on knowing the node locations to start. I could modify the script to randomly generate location and then do the triangulation… then perhaps push it back through neato to get the final graph, thereby evening out the spacing. I’ll need to think about it.
Sorry, it was a rush job of a comment; I just happened to have a bit of time to squeeze it in while waiting for a compile.
One vocabulary fail: when I said “except round the edges” at the bottom, I mean “except around the outermost part of the graph”.
OGDF has some stuff for interfacing to graphviz if that helps you any: http://www.ogdf.net/doc-ogdf-dev/namespaceogdf_1_1dot.html
Also occurred to me: the Voronoi diagram of your graph might be handy for giving a view of the size of the kingdoms’ borders. If a set of nodes make up a kingdom, then the physical extent of that kingdom can be approximated as the union of the nodes’ Voronoi polygons. Maybe you can generalise Fortune’s algorithm to generate a Voronoi diagram that takes into account a “political weight” of each node. If two neighbouring nodes have different weights, the more powerful one extends its territory further.
I will look into it when and if I feel the need to make a smarter script. For now I think I’ll keep it roughly where I’ve got it. I’ve been getting about 40-50% results that I would be okay with the changes I’ve made today, which is pretty good for more or less random generation.
Unless, of course, it’s easy to implement…. :)
I forgot to mention: in the final step of “add random edges until you have enough”, you should choose these edges from the ones in the original Delaunay triangulation, rather than just picking random pairs of nodes. This ensures that your graph stays planar! :-)
Using the edges from the triangulation also keeps most of your edges connecting to nearby nodes too. If you want to add links between distant nodes then all I can think of is the crude-but-simple approach of “pick two nodes, link them, run planarity test”.
Good points, I probably would have figured out “add to the outside nodes”. I am okay with the idea of having nodes generally be ‘close together’ if they are linked, so not having the really big edges are okay.
My first thought was that this would be linear, but it actually wouldn’t because you move away from the end from time to time. You’re going to end up with a strictly hierarchical tree when you’ve done your initial connections… but I suppose that is true of any algorithm that doesn’t introduce any cycles, isn’t it?
Yep; in fact that algorithm basically just selects a random spanning tree of the graph, with uniform probability. I like how it works from just a random walk and a flag per node, pretty cool.
Mathematics!
Pingback: Teratic Exploration | Keith Davies — In My Campaign - Keith's thoughts on RPG design and play.